
Awesome-Efficient-LLM
A curated list for Efficient Large Language Models:
- Knowledge Distillation
- Network Pruning
- Quantization
- Inference Acceleration
- Efficient MOE
- Text Compression
- Low-Rank Decomposition
- Hardware
- Tuning
- Survey
- Leaderboard
🚀 Updates
- Sep 27, 2023: Add tag
for papers accepted at NeurIPS'23.
- Sep 6, 2023: Add a new subdirectory project/ to organize those projects that are designed for developing a lightweight LLM.
- July 11, 2023: In light of the numerous publications that conducts experiments using PLMs (such as BERT, BART) currently, a new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs but have yet to be verified for their effectiveness on LLMs (not implying that they are not suitable on LLM).
💮 Contributing
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.
Knowledge Distillation
| Title & Authors | Introduction | Links |
|---|---|---|
 Specializing Smaller Language Models towards Multi-Step Reasoning Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, Tushar Khot |
 |
Github Paper |
 Distilling Script Knowledge from Large Language Models for Constrained Language Planning Siyu Yuan, Jiangjie Chen, Ziquan Fu, Xuyang Ge, Soham Shah, Charles Robert Jankowski, Yanghua Xiao, Deqing Yang |
 |
Github Paper |
SCOTT: Self-Consistent Chain-of-Thought Distillation Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, Xiang Ren |
 |
Paper |
 DISCO: Distilling Counterfactuals with Large Language Models Zeming Chen, Qiyue Gao, Antoine Bosselut, Ashish Sabharwal, Kyle Richardson |
 |
Github Paper |
 I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation Chandra Bhagavatula, Jena D. Hwang, Doug Downey, Ronan Le Bras, Ximing Lu, Lianhui Qin, Keisuke Sakaguchi, Swabha Swayamdipta, Peter West, Yejin Choi |
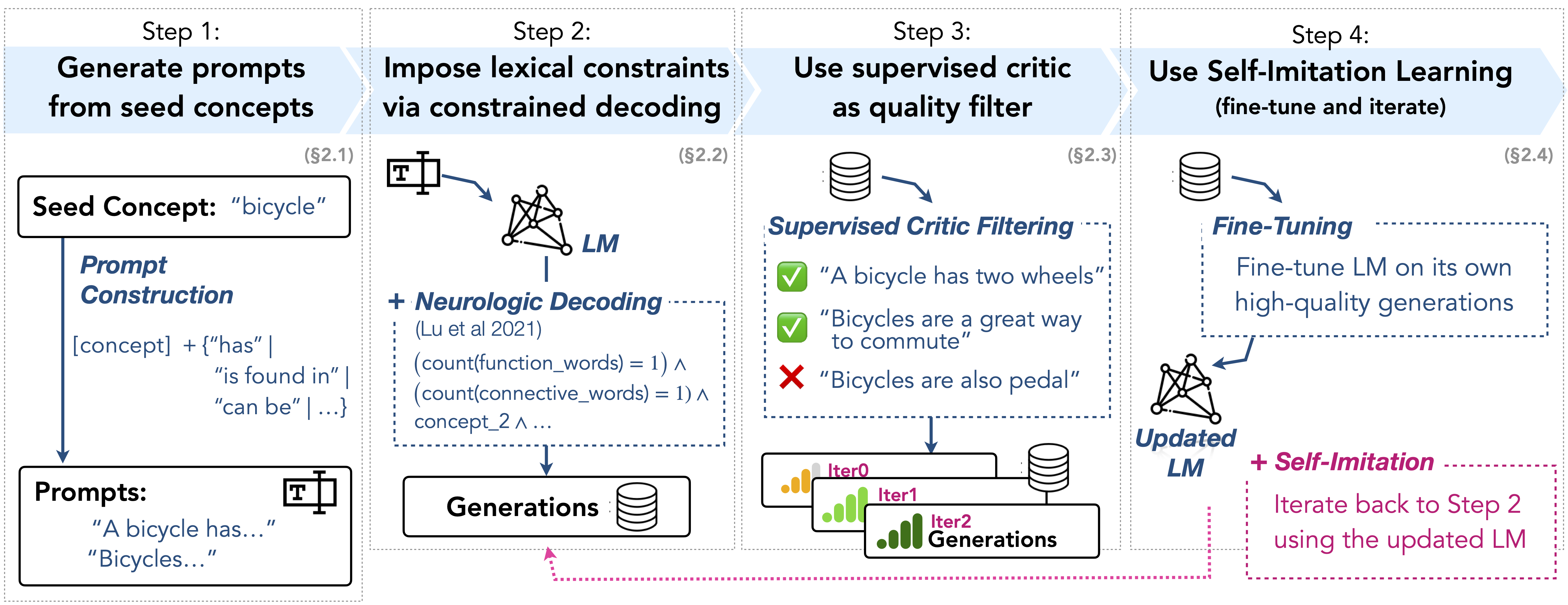 |
Github Paper Project |
 Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, Yejin Choi |
 |
Github Paper |
 Can Language Models Teach? Teacher Explanations Improve Student Performance via Theory of Mind Swarnadeep Saha, Peter Hase, and Mohit Bansal |
 |
Github Paper |
Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents Hyungjoo Chae, Yongho Song, Kai Tzu-iunn Ong, Taeyoon Kwon, Minjin Kim, Youngjae Yu, Dongha Lee, Dongyeop Kang, Jinyoung Yeo |
 |
Paper |
 PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation Gaurav Sahu, Olga Vechtomova, Dzmitry Bahdanau, Issam H. Laradji |
 |
Github Paper |
 Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Bin Sun, Xinglin Wang, Heda Wang, Kan Li |
 |
Github Paper |
 GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Yang Yang, Hongyin Tang, Keqing He, Jiahao Liu, Jingang Wang, Shu Zhao, Peng Zhang, Jie Tang |
 |
Github Paper |
 Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, Tomas Pfister |
 |
Github Paper |
Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression Jiduan Liu, Jiahao Liu, Qifan Wang, Jingang Wang, Xunliang Cai, Dongyan Zhao, Ran Lucien Wang, Rui Yan |
 |
Paper |
 Cache me if you Can: an Online Cost-aware Teacher-Student framework to Reduce the Calls to Large Language Models Ilias Stogiannidis, Stavros Vassos, Prodromos Malakasiotis, Ion Androutsopoulos |
 |
Github Paper |
 LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, Alham Fikri Aji |
 |
Github paper |
| Knowledge Distillation of Large Language Models Yuxian Gu, Li Dong, Furu Wei, Minlie Huang |
 |
Github Paper |
| Teaching Small Language Models to Reason Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, Aliaksei Severyn. |
 |
Paper |
 Large Language Model Distillation Doesn't Need a Teacher Ananya Harsh Jha, Dirk Groeneveld, Emma Strubell, Iz Beltagy |
 |
Github paper |
| The False Promise of Imitating Proprietary LLMs Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, Dawn Song |
 |
Paper |
 Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing Jaehun Jung, Peter West, Liwei Jiang, Faeze Brahman, Ximing Lu, Jillian Fisher, Taylor Sorensen, Yejin Choi |
 |
Github paper |
| PaD: Program-aided Distillation Specializes Large Models in Reasoning Xuekai Zhu, Biqing Qi, Kaiyan Zhang, Xingwei Long, Bowen Zhou |
 |
Paper |
| RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, Yuandong Tian |
 |
Paper |
| Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA Yuhan Ma, Haiqi Jiang, Chenyou Fan |
 |
Paper |
 UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, Hoifung Poon |
 |
Github Paper Project |
 Baby Llama: knowledge distillation from an ensemble of teachers trained on a small dataset with no performance penalty Inar Timiryasov, Jean-Loup Tastet |
 |
Github Paper |
| DistillSpec: Improving Speculative Decoding via Knowledge Distillation Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Rostamizadeh, Sanjiv Kumar, Jean-François Kagy, Rishabh Agarwal |
 |
Paper |
 Zephyr: Direct Distillation of LM Alignment Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, Thomas Wolf |
 |
Github Paper |
 Towards the Law of Capacity Gap in Distilling Language Models Chen Zhang, Dawei Song, Zheyu Ye, Yan Gao |
 |
Github Paper |
| Unlock the Power: Competitive Distillation for Multi-Modal Large Language Models Xinwei Li, Li Lin, Shuai Wang, Chen Qian |
 |
Paper |
| Mixed Distillation Helps Smaller Language Model Better Reasoning Li Chenglin, Chen Qianglong, Wang Caiyu, Zhang Yin |
 |
Paper |
Network Pruning







































Quantization
| Title & Authors | Introduction | Links |
|---|---|---|
 GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
 SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han |
 |
Github Paper |
 QLoRA: Efficient Finetuning of Quantized LLMs Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer |
 |
Github Paper |
 QuIP: 2-Bit Quantization of Large Language Models With Guarantees Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, Christopher De SaXQ |
 |
Github Paper |
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee |
 |
Paper |
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing Yelysei Bondarenko, Markus Nagel, Tijmen Blankevoort |
 |
Github Paper |
 LLM-FP4: 4-Bit Floating-Point Quantized Transformers Shih-yang Liu, Zechun Liu, Xijie Huang, Pingcheng Dong, Kwang-Ting Cheng |
 |
Github Paper |
Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization Jangwhan Lee, Minsoo Kim, Seungcheol Baek, Seok Joong Hwang, Wonyong Sung, Jungwook Choi |
 |
Paper |
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge Xuan Shen, Peiyan Dong, Lei Lu, Zhenglun Kong, Zhengang Li, Ming Lin, Chao Wu, Yanzhi Wang |
 |
Paper |
GPT-Zip: Deep Compression of Finetuned Large Language Models Berivan Isik, Hermann Kumbong, Wanyi Ning, Xiaozhe Yao, Sanmi Koyejo, Ce Zhang |
 |
Paper |
 Watermarking LLMs with Weight Quantization Linyang Li, Botian Jiang, Pengyu Wang, Ke Ren, Hang Yan, Xipeng Qiu |
 |
Github Paper |
 AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Song Han |
 |
Github Paper |
 RPTQ: Reorder-based Post-training Quantization for Large Language Models Zhihang Yuan and Lin Niu and Jiawei Liu and Wenyu Liu and Xinggang Wang and Yuzhang Shang and Guangyu Sun and Qiang Wu and Jiaxiang Wu and Bingzhe Wu |
 |
Github Paper |
| ZeroQuant-V2: Exploring Post-training Quantization in LLMs from Comprehensive Study to Low Rank Compensation Zhewei Yao, Xiaoxia Wu, Cheng Li, Stephen Youn, Yuxiong He |
 |
Paper |
 SqueezeLLM: Dense-and-Sparse Quantization Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer |
 |
Github Paper |
| Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling Xiuying Wei , Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, Xianglong Liu |
 |
Paper |
| Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models Yijia Zhang, Lingran Zhao, Shijie Cao, Wenqiang Wang, Ting Cao, Fan Yang, Mao Yang, Shanghang Zhang, Ningyi Xu |
 |
Paper |
| LLM-QAT: Data-Free Quantization Aware Training for Large Language Models Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra |
 |
Paper |
 SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
 OWQ: Lessons learned from activation outliers for weight quantization in large language models Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, Eunhyeok Park |
 |
Github Paper |
 Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study Peiyu Liu, Zikang Liu, Ze-Feng Gao, Dawei Gao, Wayne Xin Zhao, Yaliang Li, Bolin Ding, Ji-Rong Wen |
 |
Github Paper |
| ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats Xiaoxia Wu, Zhewei Yao, Yuxiong He |
 |
Paper |
| FPTQ: Fine-grained Post-Training Quantization for Large Language Models Qingyuan Li, Yifan Zhang, Liang Li, Peng Yao, Bo Zhang, Xiangxiang Chu, Yerui Sun, Li Du, Yuchen Xie |
 |
Paper |
| QuantEase: Optimization-based Quantization for Language Models - An Efficient and Intuitive Algorithm Kayhan Behdin, Ayan Acharya, Aman Gupta, Sathiya Keerthi, Rahul Mazumder |
 |
Paper |
| Norm Tweaking: High-performance Low-bit Quantization of Large Language Models Liang Li, Qingyuan Li, Bo Zhang, Xiangxiang Chu |
 |
Paper |
| Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs Wenhua Cheng, Weiwei Zhang, Haihao Shen, Yiyang Cai, Xin He, Kaokao Lv |
 |
Github Paper |
 QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, Qi Tian |
 |
Github Paper |
| ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers Junjie Yin, Jiahao Dong, Yingheng Wang, Christopher De Sa, Volodymyr Kuleshov |
 |
Paper |
 PB-LLM: Partially Binarized Large Language Models Yuzhang Shang, Zhihang Yuan, Qiang Wu, Zhen Dong |
 |
Github Paper |
| Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM Luoming Zhang, Wen Fei, Weijia Wu, Yefei He, Zhenyu Lou, Hong Zhou |
 |
Paper |
| QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources Zhikai Li, Xiaoxuan Liu, Banghua Zhu, Zhen Dong, Qingyi Gu, Kurt Keutzer |
 |
Paper |
| QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang |
 |
Paper |
| LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, Tuo Zhao |
 |
Paper |
| TEQ: Trainable Equivalent Transformation for Quantization of LLMs Wenhua Cheng, Yiyang Cai, Kaokao Lv, Haihao Shen |
 |
Github Paper |
| BitNet: Scaling 1-bit Transformers for Large Language Models Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei |
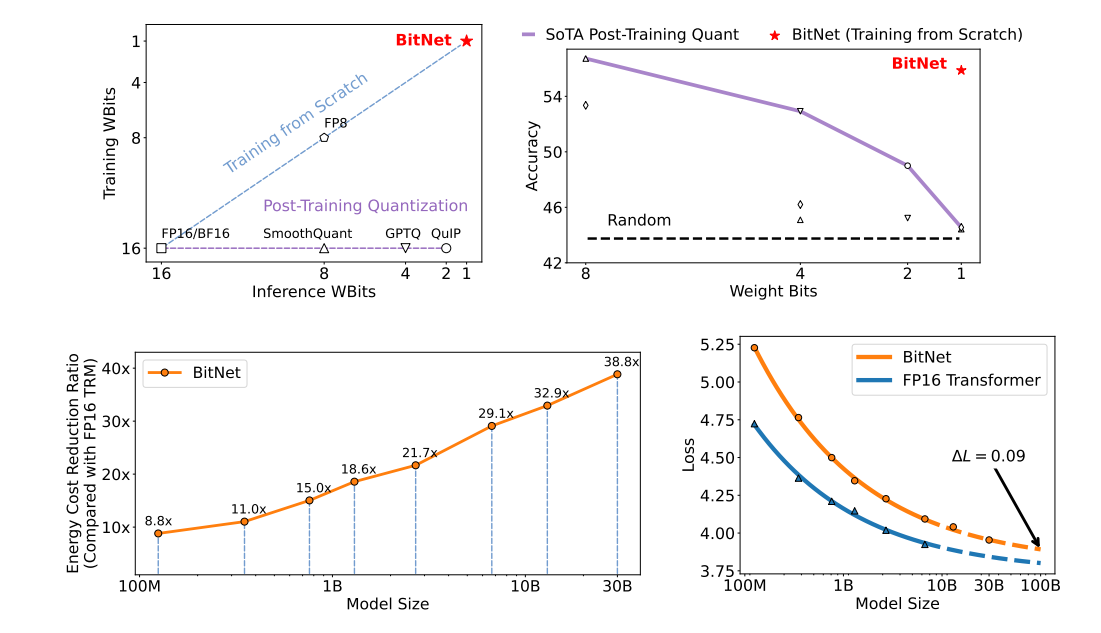 |
Paper |
| Atom: Low-bit Quantization for Efficient and Accurate LLM Serving Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, Baris Kasikci |
 |
Paper |
| AWEQ: Post-Training Quantization with Activation-Weight Equalization for Large Language Models Baisong Li, Xingwang Wang, Haixiao Xu |
 |
Paper |
 AFPQ: Asymmetric Floating Point Quantization for LLMs Yijia Zhang, Sicheng Zhang, Shijie Cao, Dayou Du, Jianyu Wei, Ting Cao, Ningyi Xu |
 |
Github Paper |
| A Speed Odyssey for Deployable Quantization of LLMs Qingyuan Li, Ran Meng, Yiduo Li, Bo Zhang, Liang Li, Yifan Lu, Xiangxiang Chu, Yerui Sun, Yuchen Xie |
 |
Paper |
 LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim |
 |
Github Paper |
| Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization Jinhao Li, Shiyao Li, Jiaming Xu, Shan Huang, Yaoxiu Lian, Jun Liu, Yu Wang, Guohao Dai |
 |
Paper |
 SmoothQuant+: Accurate and Efficient 4-bit Post-Training WeightQuantization for LLM Jiayi Pan, Chengcan Wang, Kaifu Zheng, Yangguang Li, Zhenyu Wang, Bin Feng |
 |
Github Paper |
| ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks Xiaoxia Wu, Haojun Xia, Stephen Youn, Zhen Zheng, Shiyang Chen, Arash Bakhtiari, Michael Wyatt, Yuxiong He, Olatunji Ruwase, Leon Song, Zhewei Yao |
 |
Github Paper |
 Extreme Compression of Large Language Models via Additive Quantization Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh |
 |
Github Paper |
Inference Acceleration










































Efficient MOE
| Title & Authors | Introduction | Links |
|---|---|---|
| SiDA: Sparsity-Inspired Data-Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models Zhixu Du, Shiyu Li, Yuhao Wu, Xiangyu Jiang, Jingwei Sun, Qilin Zheng, Yongkai Wu, Ang Li, Hai "Helen" Li, Yiran Chen |
 |
Paper |
 Fast Inference of Mixture-of-Experts Language Models with Offloading Artyom Eliseev, Denis Mazur |
 |
Github Paper |
 SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention Róbert Csordás, Piotr Piękos, Kazuki Irie, Jürgen Schmidhuber |
 |
Github Paper |
Text Compression
| Title & Authors | Introduction | Links |
|---|---|---|
EntropyRank: Unsupervised Keyphrase Extraction via Side-Information Optimization for Language Model-based Text Compression Alexander Tsvetkov. Alon Kipnis |
 |
Paper |
| LLMZip: Lossless Text Compression using Large Language Models Chandra Shekhara Kaushik Valmeekam, Krishna Narayanan, Dileep Kalathil, Jean-Francois Chamberland, Srinivas Shakkottai |
 |
Paper | Unofficial Github |
 Adapting Language Models to Compress Contexts Alexis Chevalier, Alexander Wettig, Anirudh Ajith, Danqi Chen |
 |
Github Paper |
| In-context Autoencoder for Context Compression in a Large Language Model Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, Furu Wei |
 |
Paper |
| Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Model Guanghui Qin, Corby Rosset, Ethan C. Chau, Nikhil Rao, Benjamin Van Durme |
 |
Paper |
| Boosting LLM Reasoning: Push the Limits of Few-shot Learning with Reinforced In-Context Pruning Xijie Huang, Li Lyna Zhang, Kwang-Ting Cheng, Mao Yang |
 |
Paper |
Low-Rank Decomposition
| Title & Authors | Introduction | Links |
|---|---|---|
 LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, Tuo Zhao |
 |
Github Paper |
 Matrix Compression via Randomized Low Rank and Low Precision Factorization Rajarshi Saha, Varun Srivastava, Mert Pilanci |
 |
Github Paper |
| TensorGPT: Efficient Compression of the Embedding Layer in LLMs based on the Tensor-Train Decomposition Mingxue Xu, Yao Lei Xu, Danilo P. Mandic |
 |
Paper |
| LORD: Low Rank Decomposition Of Monolingual Code LLMs For One-Shot Compression Ayush Kaushal, Tejas Vaidhya, Irina Rish |
 |
Paper Project |
 Rethinking Compression: Reduced Order Modelling of Latent Features in Large Language Models Arnav Chavan, Nahush Lele, Deepak Gupta |
 |
Github Paper |
Hardware
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré. [Paper][Github]
Efficiently Scaling Transformer Inference. Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, Jeff Dean. [Paper]
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, Ce Zhang. [Paper][Github]
Efficient Memory Management for Large Language Model Serving with PagedAttention. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, Ion Stoica. [Paper][Github]
Efficient LLM Inference on CPUs. Haihao Shen, Hanwen Chang, Bo Dong, Yu Luo, Hengyu Meng. [Paper][Github]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models. Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. [Paper]
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models. Yonggan Fu, Yongan Zhang, Zhongzhi Yu, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, Yingyan Lin. [Paper]
- Rethinking Memory and Communication Cost for Efficient Large Language Model Training. Chan Wu, Hanxiao Zhang, Lin Ju, Jinjing Huang, Youshao Xiao, Zhaoxin Huan, Siyuan Li, Fanzhuang Meng, Lei Liang, Xiaolu Zhang, Jun Zhou. [Paper]
- Chameleon: a Heterogeneous and Disaggregated Accelerator System for Retrieval-Augmented Language Models. Wenqi Jiang, Marco Zeller, Roger Waleffe, Torsten Hoefler, Gustavo Alonso. [Paper]
- FlashDecoding++: Faster Large Language Model Inference on GPUs. Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Hanyu Dong, Yu Wang. [Paper]
Striped Attention: Faster Ring Attention for Causal Transformers. William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, Jonathan Ragan-Kelley. [Paper][Github]
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU. Yixin Song, Zeyu Mi, Haotong Xie, Haibo Chen. [Paper][Github]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory. Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, Mehrdad Farajtabar. [Paper]
- FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGA. Shulin Zeng, Jun Liu, Guohao Dai, Xinhao Yang, Tianyu Fu, Hongyi Wang, Wenheng Ma, Hanbo Sun, Shiyao Li, Zixiao Huang, Yadong Dai, Jintao Li, Zehao Wang, Ruoyu Zhang, Kairui Wen, Xuefei Ning, Yu Wang. [Paper]
- Efficient LLM inference solution on Intel GPU. Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu. [Paper][Github]





Tuning
- CPET: Effective Parameter-Efficient Tuning for Compressed Large Language Models. Weilin Zhao, Yuxiang Huang, Xu Han, Zhiyuan Liu, Zhengyan Zhang, Maosong Sun. [Paper]
ReMax: A Simple, Effective, and Efficient Method for Aligning Large Language Models. Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo. [Paper][Github]
- TRANSOM: An Efficient Fault-Tolerant System for Training LLMs. Baodong Wu, Lei Xia, Qingping Li, Kangyu Li, Xu Chen, Yongqiang Guo, Tieyao Xiang, Yuheng Chen, Shigang Li. [Paper]
- DEFT: Data Efficient Fine-Tuning for Large Language Models via Unsupervised Core-Set Selection. Devleena Das, Vivek Khetan. [Paper]
LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models. Jianxin Yang. [Paper][Github]
Sparse Fine-tuning for Inference Acceleration of Large Language Models. Eldar Kurtic, Denis Kuznedelev, Elias Frantar, Michael Goin, Dan Alistarh. [Paper][Github][Github]
ComPEFT: Compression for Communicating Parameter Efficient Updates via Sparsification and Quantization. Prateek Yadav, Leshem Choshen, Colin Raffel, Mohit Bansal. [Paper][Github]
- Towards Better Parameter-Efficient Fine-Tuning for Large Language Models: A Position Paper. Chengyu Wang, Junbing Yan, Wei Zhang, Jun Huang. [Paper]
SPT: Fine-Tuning Transformer-based Language Models Efficiently with Sparsification. Yuntao Gui, Xiao Yan, Peiqi Yin, Han Yang, James Cheng. [Paper][Github]





Survey
- A Survey on Model Compression for Large Language Models. Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang. [Paper]
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey. Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang. [Paper][Github]
Efficient Large Language Models: A Survey. Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang. [Paper][Github]
- Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems. Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, Tianqi Chen, Zhihao Jia. [Paper]
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models. Guangji Bai, Zheng Chai, Chen Ling, Shiyu Wang, Jiaying Lu, Nan Zhang, Tingwei Shi, Ziyang Yu, Mengdan Zhu, Yifei Zhang, Carl Yang, Yue Cheng, Liang Zhao. [Paper][Github]



Leaderboard
| Platform | Access |
|---|---|
| Huggingface LLM Perf Leaderboard | [Source] |
| LLMPerf Leaderboard | [Source] |