
![]()
A command-line toolkit to extract text content and category data from Wikipedia dump files
About
WP2TXT extracts text and category data from Wikipedia dump files (encoded in XML / compressed with Bzip2), removing MediaWiki markup and other metadata.
Changelog
May 2023
- Problems caused by too many parallel processors are addressed by setting the upper limit on the number of processors to 8.
April 2023
- File split/delete issues fixed
January 2023
- Bug related to command line arguments fixed
- Code cleanup introducing Rubocop
December 2022
- Docker images available via Docker Hub
November 2022
- Code added to suppress "Invalid byte sequence error" when an ilegal UTF-8 character is input.
August 2022
- A new option
--category-onlyhas been added. When this option is enabled, only the title and category information of the article is extracted. - A new option
--summary-onlyhas been added. If this option is enabled, only the title, category information, and opening paragraphs of the article will be extracted. - Text conversion with the current version of WP2TXT is more than 2x times faster than the previous version due to parallel processing of multiple files (the rate of speedup depends on the CPU cores used for processing).
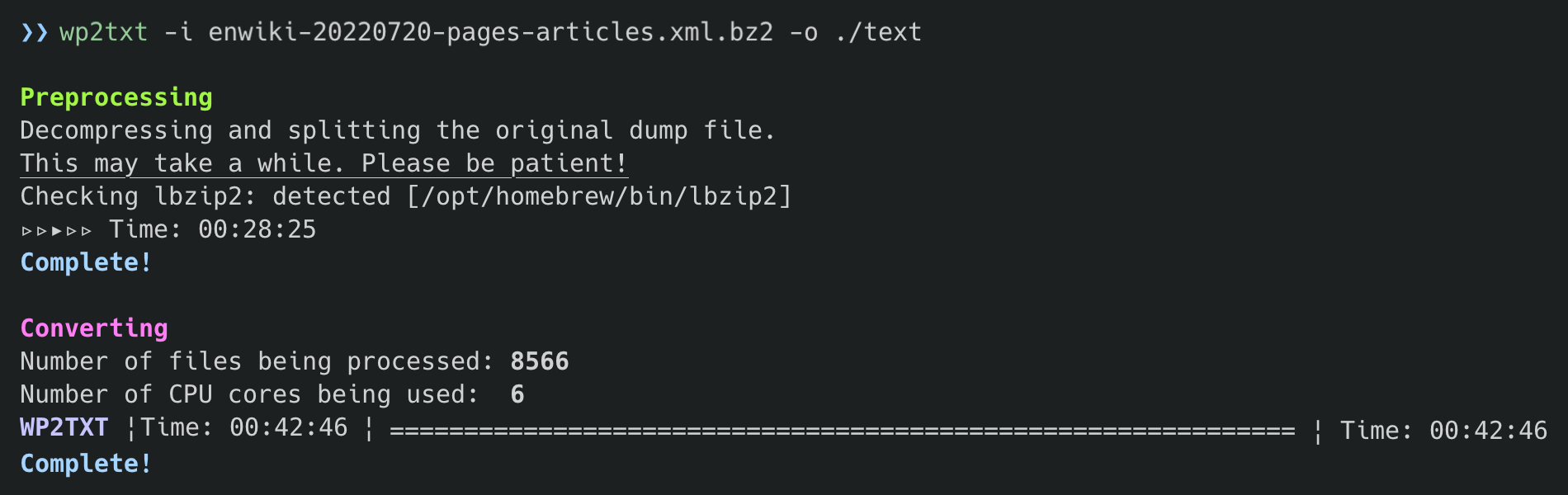
Screenshot
Environment
- WP2TXT 1.0.1
- MacBook Pro (2021 Apple M1 Pro)
- enwiki-20220720-pages-articles.xml.bz2 (19.98 GB)
In the above environment, the process (decompression, splitting, extraction, and conversion) to obtain the plain text data of the English Wikipedia takes less than 1.5 hours.
Features
- Converts Wikipedia dump files in various languages
- Creates output files of specified size
- Allows specifying ext elements (page titles, section headers, paragraphs, list items) to be extracted
- Allows extracting category information of the article
- Allows extracting opening paragraphs of the article
Setting Up
WP2TXT on Docker
- Install Docker Desktop (Mac/Windows/Linux)
- Execute
dockercommand in a terminal:
docker run -it -v /Users/me/localdata:/data yohasebe/wp2txt- Make sure to Replace
/Users/me/localdatawith the full path to the data directory in your local computer
- The Docker image will begin downloading and a bash prompt will appear when finished.
- The
wp2txtcommand will be avalable anywhare in the Docker container. Use the/datadirectory as the location of the input dump files and the output text files.
IMPORTANT:
- Configure Docker Desktop resource settings (number of cores, amount of memory, etc.) to get the best performance possible.
- When running the
wp2txtcommand inside a Docker container, be sure to set the output directory to somewhere in the mounted local directory specified by thedocker runcommand.
WP2TXT on MacOS and Linux
WP2TXT requires that one of the following commands be installed on the system in order to decompress bz2 files:
lbzip2(recommended)pbzip2bzip2
In most cases, the bzip2 command is pre-installed on the system. However, since lbzip2 can use multiple CPU cores and is faster than bzip2, it is recommended that you install it additionally. WP2TXT will attempt to find the decompression command available on your system in the order listed above.
If you are using MacOS with Homebrew installed, you can install lbzip2 with the following command:
$ brew install lbzip2
WP2TXT on Windows
Install Bzip2 for Windows and set the path so that WP2TXT can use the bunzip2.exe command. Alternatively, you can extract the Wikipedia dump file in your own way and process the resulting XML file with WP2TXT.
Installation
WP2TXT command
$ gem install wp2txt
Wikipedia Dump File
Download the latest Wikipedia dump file for the desired language at a URL such as
https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
Here, enwiki refers to the English Wikipedia. To get the Japanese Wikipedia dump file, for instance, change this to jawiki (Japanese). In doing so, note that there are two instances of enwiki in the URL above.
Alternatively, you can also select Wikipedia dump files created on a specific date from here. Make sure to download a file named in the following format:
xxwiki-yyyymmdd-pages-articles.xml.bz2
where xx is language code such as en (English)" or ja (japanese), and yyyymmdd is the date of creation (e.g. 20220801).
Basic Usage
Suppose you have a folder with a wikipedia dump file and empty subfolders organized as follows:
.
├── enwiki-20220801-pages-articles.xml.bz2
├── /xml
├── /text
├── /category
└── /summary
Decompress and Split
The following command will decompress the entire wikipedia data and split it into many small (approximately 10 MB) XML files.
$ wp2txt --no-convert -i ./enwiki-20220801-pages-articles.xml.bz2 -o ./xml
Note: The resulting files are not well-formed XML. They contain part of the orignal XML extracted from the Wikipedia dump file, taking care to ensure that the content within the tag is not split into multiple files.
Extract plain text from MediaWiki XML
$ wp2txt -i ./xml -o ./text
Extract only category info from MediaWiki XML
$ wp2txt -g -i ./xml -o ./category
Extract opening paragraphs from MediaWiki XML
$ wp2txt -s -i ./xml -o ./summary
Extract directly from bz2 compressed file
It is possible (though not recommended) to 1) decompress the dump files, 2) split the data into files, and 3) extract the text just one line of command. You can automatically remove all the intermediate XML files with -x option.
$ wp2txt -i ./enwiki-20220801-pages-articles.xml.bz2 -o ./text -x
Sample Output
Output contains title, category info, paragraphs
$ wp2txt -i ./input -o /output
Output containing title and category only
$ wp2txt -g -i ./input -o /output
Output containing title, category, and summary
$ wp2txt -s -i ./input -o /output
Command Line Options
Command line options are as follows:
Usage: wp2txt [options]
where [options] are:
-i, --input Path to compressed file (bz2) or decompressed file (xml), or path to directory containing files of the latter format
-o, --output-dir=<s> Path to output directory
-c, --convert, --no-convert Output in plain text (converting from XML) (default: true)
-a, --category, --no-category Show article category information (default: true)
-g, --category-only Extract only article title and categories
-s, --summary-only Extract only article title, categories, and summary text before first heading
-f, --file-size=<i> Approximate size (in MB) of each output file (default: 10)
-n, --num-procs Number of proccesses (up to 8) to be run concurrently (default: max num of available CPU cores minus two)
-x, --del-interfile Delete intermediate XML files from output dir
-t, --title, --no-title Keep page titles in output (default: true)
-d, --heading, --no-heading Keep section titles in output (default: true)
-l, --list Keep unprocessed list items in output
-r, --ref Keep reference notations in the format [ref]...[/ref]
-e, --redirect Show redirect destination
-m, --marker, --no-marker Show symbols prefixed to list items, definitions, etc. (Default: true)
-b, --bz2-gem Use Ruby's bzip2-ruby gem instead of a system command
-v, --version Print version and exit
-h, --help Show this message
Caveats
- Some data, such as mathematical formulas and computer source code, will not be converted correctly.
- Some text data may not be extracted correctly for various reasons (incorrect matching of begin/end tags, language-specific formatting rules, etc.).
- The conversion process can take longer than expected. When dealing with a huge data set such as the English Wikipedia on a low-spec environment, it can take several hours or more.
Useful Links
Author
- Yoichiro Hasebe ([email protected])
References
The author will appreciate your mentioning one of these in your research.
- Yoichiro HASEBE. 2006. Method for using Wikipedia as Japanese corpus. Doshisha Studies in Language and Culture 9(2), 373-403.
- 長谷部陽一郎. 2006. Wikipedia日本語版をコーパスとして用いた言語研究の手法. 『言語文化』9(2), 373-403.
Or use this BibTeX entry:
@misc{wp2txt_2023,
author = {Yoichiro Hasebe},
title = {WP2TXT: A command-line toolkit to extract text content and category data from Wikipedia dump files},
url = {https://github.com/yohasebe/wp2txt},
year = {2023}
}
License
This software is distributed under the MIT License. Please see the LICENSE file.