
Fine-tuning Wav2vec 2.0 for SER
Official implementation for the paper Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition. Submitted to ICASSP 2022.
Libraries and dependencies
- pytorch
- pytorch-lightning
- fairseq (For Wav2vec)
- huggingface transformers (For Wav2vec2)
- faiss (For running clustering)
Faiss can be skipped if you are not running clustering scripts.
Or you can simply check the DockerFile at docker/Dockerfile for our setup.
To train the first phase wav2vec model of P-TAPT, you'll need the the pretrained wav2vec model checkpoint from Facebook AI Research, which can be obtained here.
- Code just switched from hard-coding to passing arguments, not sure every scripts are working as expected.
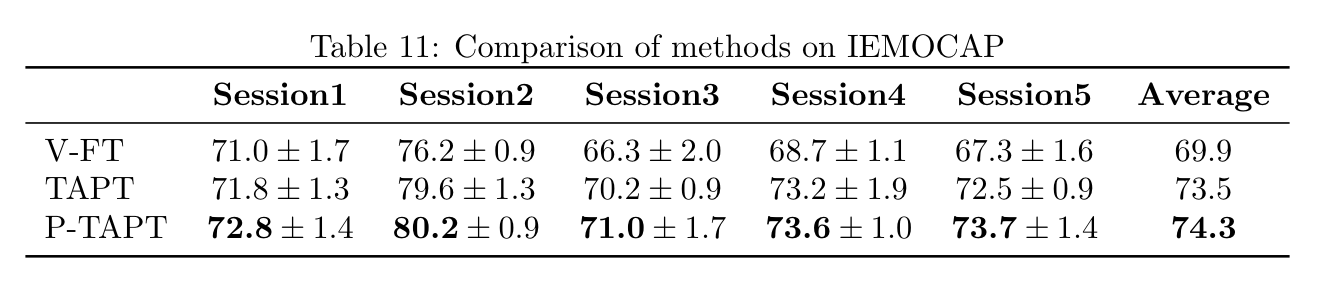
Reproduce on IEMOCAP
Result averaged over 5 runs (only the fine-tuning stage is ran 5 times) with standard deviation:
Prepare IEMOCAP
Obtain IEMOCAP from USC
cd Dataset/IEMOCAP &&
python make_16k.py IEMOCAP_DIR &&
python gen_meta_label.py IEMOCAP_DIR &&
python generate_labels_sessionwise.py &&
cd ../..
Run scripts
- P-TAPT:
bash bin/run_exp_iemocap.sh Dataset/IEMOCAP/Audio_16k/ Dataset/IEMOCAP/labels_sess/label_{SESSION_TO_TEST}.json OUTPUT_DIR GPU_ID P-TAPT NUM_EXPS WAV2VEC_CKPT_PATH - TAPT:
bash bin/run_exp_iemocap_baseline.sh Dataset/IEMOCAP/Audio_16k/ Dataset/IEMOCAP/labels_sess/label_{SESSION_TO_TEST}.json OUTPUT_DIR GPU_ID TAPT NUM_EXPS - V-FT:
bash bin/run_exp_iemocap_vft.sh Dataset/IEMOCAP/Audio_16k/ Dataset/IEMOCAP/labels_sess/label_{SESSION_TO_TEST}.json OUTPUT_DIR GPU_ID V-FT NUM_EXPS
The OUTPUT_DIR should not be exist and different for each method, note that it will take a long time since we need to run NUM_EXPS and average. The statistics will be at OUTPUT_DIR/{METHOD}.log along with some model checkpoints. Note that it takes a long time and lots of VRAM, if you are concerned at computation, try lower the batch size (but the results may not be as expected).
Run the training scripts on your own dataset
You will need a directory containing all the training wave files sampled at 16kHz, and a json file which contains the emotion label, and the training/validation/testing splits in the following format:
{
"Train": {
audio_filename1: angry,
audio_filename2: sad,
...
}
"Val": {
audio_filename1: neutral,
audio_filename2: happy,
...
}
"Test": {
audio_filename1: neutral,
audio_filename2: angry,
...
}
}
- If the Test has zero elements
"Test: {}", no testing will be performed, same rule holds for validation. - Put all your dataset in the following structure, we will be mounting this directory to the container.
V-FT
python run_downstream_custom_multiple_fold.py --precision 16 \
--num_exps NUM_EXP \
--datadir Audio_Dir \
--labeldir LABEL_DIR \
--saving_path SAVING_CKPT_PATH \
--outputfile OUTPUT_FILE
--max_epochs: The epoch to train on the custom dataset, default to 15--maxseqlen: maximum input duration in sec, truncate if exceed, default to 12--labeldir: A directory contains all the label files to be evaluate (in folds)--saving_pathPath for audio generated checkpoints--outputfile: A log file for outputing the test statistics
TAPT
Task adaptive training stage
python run_baseline_continueFT.py --saving_path SAVING_CKPT_PATH \
--precision 16 \
--datadir Audio_Dir \
--labelpath LABEL_DIR \
--training_step TAPT_STEPS \
--warmup_step 100 \
--save_top_k 1 \
--lr 1e-4 \
--batch_size 64 \
--use_bucket_sampler
Run the fine-tuning stage
python run_downstream_custom_multiple_fold.py --precision 16 \
--num_exps NUM_EXP \
--datadir Audio_Dir \
--labeldir LABEL_DIR \
--saving_path SAVING_CKPT_PATH \
--pretrained_path PRETRAINED_PATH \
--outputfile OUTPUT_FILE
--pretrained_path: The model path from the output of previousrun_baseline_continueFT.py
Train the first phase wav2vec
python run_pretrain.py --datadir Audio_Dir \
--labelpath Label_Path
--labeling_method hard \
--saving_path Saving_Path \
--training_step 10000 \
--save_top_k 1 \
--wav2vecpath Wav2vecCKPT \
--precision 16
This will output a w2v-{epoch:02d}-{valid_loss:.2f}-{valid_acc:.2f}.ckpt file according to the best performance on the validation split (randomly split from training set).
--training_step: The total number of steps to train on the custom dataset, scale down if it converges quickly--precision: Using amp or not, default to 32, specifiy 16 for amp training--lr: Learning rate, default to 1e-4--nworkers: number of cpu workers for dataloader, default to 4--batch_size: batch size used for training, default to 64 The output model will be saved atpretrain/checkpointsas default, you can change it by passing the--saving_pathoption.
Clustering
python cluster.py --model_path Model_Path \
--labelpath Label_Path \
--datadir Audio_Dir \
--outputdir Output_Dir \
--model_type wav2vec \
--sample_ratio 1.0 \
--num_clusters "64,512,4096"
--model_path: The output of the previous scriptrun_pretrain.py--num_clusters: Number of clusters to run, scale down if you have lesser training data--sample_ratio: Ratio of training data to subsample for training k-means, scale down if you have a large amount of training data After getting the primary Wav2vec feature extractor, we are ready to cluster. Run the above commands with different--model_typeyou are using. Typically the first round will bewav2vec, but you can also do iterative pseudo-labeling onwav2vec2. The default clusters are assigned as8,64,512,4096. You can change this by passing a comma delimited string to--num_clusters, i.e.--num_clusters 8,64,512,4096. Following this example, there will be 5 files written in theOutput_Dir: Four json label files of each number of cluster, and one json file merging label of all cluster numbers, which is used in the second phase. After clustering, you can run therun_second.pyto train on the new generated labels.
Train the second phase wav2vec2
python run_second.py --datadir Audio_Dir \
--labelpath Label_Path \
--precision 16 \
--num_clusters "64,512,4096" \
--training_step 20000 \
--warmup_step 100 \
--saving_path Save_Path \
--save_top_k 1 \
--use_bucket_sampler \
--dynamic_batch
Label_Path is the labelfile we get from the first round clustering. To specify our own custom clusters as done in the first phase, use num_clusters option similar to the first round clustering (default is 8,64,512,4096).
This will write a w2v2-{epoch:02d}-{valid_loss:.2f}-{valid_acc:.2f}.ckpt for your best model on validation (if you have validation set), and a last.ckpt for the checkpoint of the last epoch.
--num_clusters: Number of clusters to run, should be consistent with what you passed tocluster.py--warmup_step: Number of warmup steps for ramping up the learning rate--use_bucket_sampler: Bucketing the training utterances for faster training speed.
Run the fine-tuning stage
python run_downstream_custom_multiple_fold.py --precision 16 \
--num_exps NUM_EXP \
--datadir Audio_Dir \
--labeldir LABEL_DIR \
--saving_path SAVING_CKPT_PATH \
--pretrained_path PRETRAINED_PATH \
--outputfile OUTPUT_FILE
--pretrained_path: The model path from the output of previousrun_second.py