
Convolutional Neural Network Adversarial Attacks
Note: I am aware that there are some issues with the code, I will update this repository soon (Also will move away from cv2 to PIL).
This repo is a branch off of CNN Visualisations because it was starting to get bloated. It contains following CNN adversarial attacks implemented in Pytorch:
- Fast Gradient Sign, Untargeted [1]
- Fast Gradient Sign, Targeted [1]
- Gradient Ascent, Adversarial Images [2]
- Gradient Ascent, Fooling Images (Unrecognizable images predicted as classes with high confidence) [2]
It will also include more adverisarial attack and defenses techniques in the future as well.
The code uses pretrained AlexNet in the model zoo. You can simply change it with your model but don't forget to change target class parameters as well.
All images are pre-processed with mean and std of the ImageNet dataset before being fed to the model. None of the code uses GPU as these operations are quite fast (for a single image). You can make use of gpu with very little effort. The examples below include numbers in the brackets after the description, like Mastiff (243), this number represents the class id in the ImageNet dataset.
I tried to comment on the code as much as possible, if you have any issues understanding it or porting it, don't hesitate to reach out.
Below, are some sample results for each operation.
Fast Gradient Sign - Untargeted
In this operation we update the original image with signs of the received gradient on the first layer. Untargeted version aims to reduce the confidence of the initial class. The code breaks as soon as the image stops being classified as the original label.
| Predicted as Eel (390) Confidence: 0.96 |
Adversarial Noise | Predicted as Blowfish (397) Confidence: 0.81 |
 |
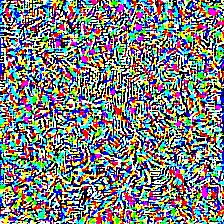 |
 |
| Predicted as Snowbird (13) Confidence: 0.99 |
Adversarial Noise | Predicted as Chickadee (19) Confidence: 0.95 |
 |
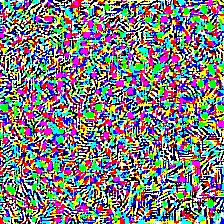 |
 |
Fast Gradient Sign - Targeted
Targeted version of FGS works almost the same as the untargeted version. The only difference is that we do not try to minimize the original label but maximize the target label. The code breaks as soon as the image is predicted as the target class.
| Predicted as Apple (948) Confidence: 0.95 |
Adversarial Noise | Predicted as Rock python (62) Confidence: 0.16 |
 |
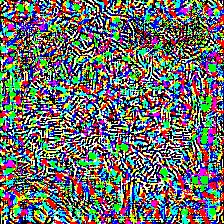 |
 |
| Predicted as Apple (948) Confidence: 0.95 |
Adversarial Noise | Predicted as Mud turtle (35) Confidence: 0.54 |
| |
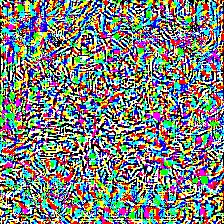 |
 |
Gradient Ascent - Fooling Image Generation
In this operation we start with a random image and continously update the image with targeted backpropagation (for a certain class) and stop when we achieve target confidence for that class. All of the below images are generated from pretrained AlexNet to fool it.
| Predicted as Zebra (340) Confidence: 0.94 |
Predicted as Bow tie (457) Confidence: 0.95 |
Predicted as Castle (483) Confidence: 0.99 |
 |
 |
 |
Gradient Ascent - Adversarial Image Generation
This operation works exactly same as the previous one. The only important thing is that keeping learning rate a bit smaller so that the image does not receive huge updates so that it will continue to look like the originial. As it can be seen from samples, on some images it is almost impossible to recognize the difference between two images but on others it can clearly be observed that something is wrong. All of the examples below were created from and tested on AlexNet to fool it.
| Predicted as Eel (390) Confidence: 0.96 |
Predicted as Apple (948) Confidence: 0.95 |
Predicted as Snowbird (13) Confidence: 0.99 |
| |
|
|
| Predicted as Banjo (420) Confidence: 0.99 |
Predicted as Abacus (398) Confidence: 0.99 |
Predicted as Dumbell (543) Confidence: 1 |
 |
 |
 |
Requirements:
torch >= 0.2.0.post4
torchvision >= 0.1.9
numpy >= 1.13.0
opencv >= 3.1.0
References:
[1] I. J. Goodfellow, J. Shlens, C. Szegedy. Explaining and Harnessing Adversarial Examples https://arxiv.org/abs/1412.6572
[2] A. Nguyen, J. Yosinski, J. Clune. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images https://arxiv.org/abs/1412.1897