
AdaBound-Tensorflow
Simple Tensorflow implementation of "Adaptive Gradient Methods with Dynamic Bound of Learning Rate" (ICLR 2019)
Hyperparameter
learning_rate= 0.01final_lr= 0.1beta1= 0.9beta2= 0.999
Usage
from AdaBound import AdaBoundOptimizer
train_op = AdaBoundOptimizer(learning_rate=0.01, final_lr=0.1, beta1=0.9, beta2=0.999, amsbound=False).minimize(loss)Network Architecture
x = fully_connected(inputs=images, units=100)
x = relu(x)
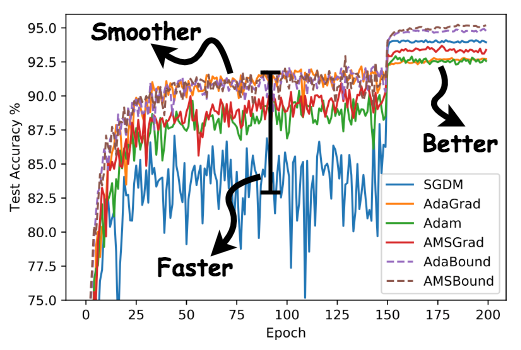
logits = fully_connected(inputs=x, units=10)Fashion-mnist Result
batch_size=32, lr=0.01, final_lr=0.1, beta1=0.9, beta2=0.99


| Optimizer | Best Test Acc |
|---|---|
| SGD | 86.33% |
| Adam | 85.81% |
| AMSGrad | 87.28% |
| AdaBound | 87.68% |
| AMSBound | 87.76% |
batch_size=32, lr=0.01, final_lr=0.1, beta1=0.9, beta2=0.999


| Optimizer | Best Test Acc |
|---|---|
| SGD | 86.33% |
| Adam | 86.14% |
| AMSGrad | 86.63% |
| AdaBound | 86.88% |
| AMSBound | 87.25% |
Related works
Author
Junho Kim