
多标签文本分类
数据集
数据来源:2020语言与智能技术竞赛:事件抽取任务
模型训练
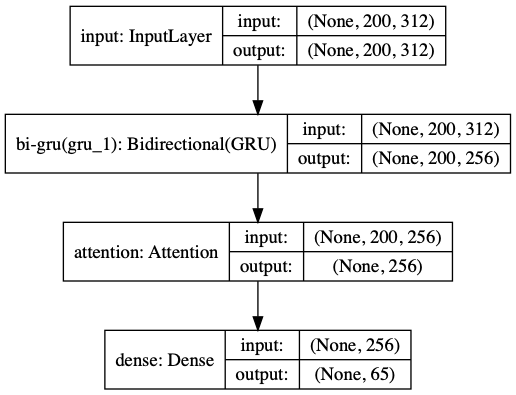
- 模型结构:采用ALBERT对文本进行特征提取,最大文本长度为200,采用的深度学习模型如下:
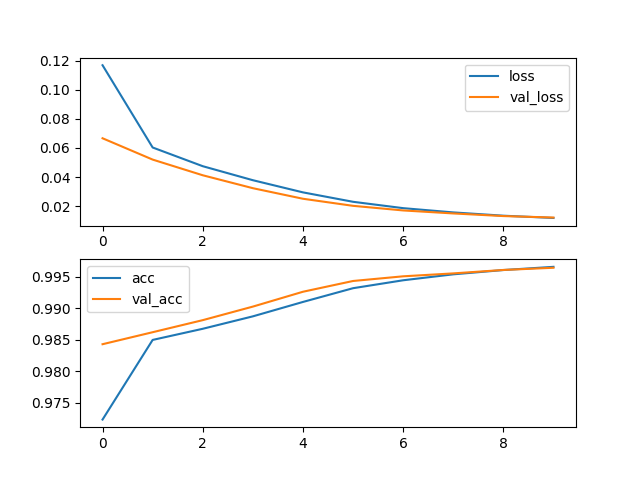
- 模型训练效果如下图:
模型评估
本项目采用hamming loss对多标签分类进行评估,结果如下:
precision recall f1-score support
0 1.0000 0.9167 0.9565 12
1 1.0000 0.1250 0.2222 8
2 1.0000 0.4000 0.5714 10
3 1.0000 0.6364 0.7778 11
4 0.9375 0.7895 0.8571 19
5 0.9355 0.8286 0.8788 35
6 1.0000 0.8750 0.9333 24
7 0.9211 0.9333 0.9272 150
8 1.0000 1.0000 1.0000 36
9 0.9286 0.8125 0.8667 16
10 0.5000 0.0667 0.1176 15
11 1.0000 0.2500 0.4000 4
12 0.9286 0.8667 0.8966 15
13 1.0000 0.5000 0.6667 14
14 0.8333 0.8333 0.8333 6
15 1.0000 0.8750 0.9333 16
16 1.0000 0.2500 0.4000 8
17 0.8936 0.7925 0.8400 106
18 1.0000 1.0000 1.0000 9
19 0.9697 0.9697 0.9697 33
20 0.9697 0.7442 0.8421 43
21 1.0000 0.8889 0.9412 9
22 1.0000 1.0000 1.0000 12
23 0.8667 0.7222 0.7879 18
24 0.9091 0.7143 0.8000 14
25 0.9877 0.9091 0.9467 88
26 1.0000 0.7778 0.8750 9
27 0.9688 0.9688 0.9688 32
28 0.9630 0.8966 0.9286 29
29 0.8571 0.8571 0.8571 21
30 1.0000 1.0000 1.0000 14
31 1.0000 0.7000 0.8235 10
32 1.0000 0.7692 0.8696 13
33 0.0000 0.0000 0.0000 7
34 1.0000 0.5556 0.7143 9
35 1.0000 0.7500 0.8571 16
36 0.9048 0.7037 0.7917 27
37 0.9310 0.7714 0.8438 35
38 0.8545 0.8393 0.8468 56
39 0.9000 0.8182 0.8571 33
40 0.9286 0.8125 0.8667 16
41 0.9665 0.9484 0.9573 213
42 1.0000 0.9091 0.9524 11
43 0.7000 0.7778 0.7368 18
44 1.0000 1.0000 1.0000 11
45 1.0000 0.7317 0.8451 41
46 0.9412 0.8421 0.8889 19
47 0.9091 1.0000 0.9524 10
48 0.5000 0.2000 0.2857 5
49 1.0000 0.2308 0.3750 13
50 0.9333 0.9859 0.9589 71
51 0.8500 0.7727 0.8095 22
52 0.9688 0.9688 0.9688 32
53 1.0000 0.7778 0.8750 9
54 1.0000 0.7500 0.8571 8
55 1.0000 0.8889 0.9412 9
56 0.0000 0.0000 0.0000 7
57 0.8571 0.5000 0.6316 24
58 0.0000 0.0000 0.0000 3
59 1.0000 0.4000 0.5714 5
60 1.0000 0.9259 0.9615 27
61 1.0000 1.0000 1.0000 14
62 1.0000 0.8571 0.9231 14
63 0.8750 0.7778 0.8235 9
64 1.0000 0.7500 0.8571 4
micro avg 0.9424 0.8292 0.8822 1657
macro avg 0.8983 0.7218 0.7791 1657
weighted avg 0.9308 0.8292 0.8669 1657
samples avg 0.8675 0.8496 0.8517 1657
accuracy: 0.7983978638184246
hamming loss: 0.0037691280681934887
模型预测
在新数据上进行预测,结果如下:
预测语句: 北京时间6月7日,中国男足在广州天河体育场与菲律宾进行了一场热身赛,最终国足以2-0击败了对手,里皮也赢得了再度执教国足后的首场比赛胜利! 预测事件类型: 竞赛行为-胜负
预测语句: 巴西亚马孙雨林大火持续多日,引发全球关注。 预测事件类型: 灾害/意外-起火
预测语句: 19里加大师赛资格赛前两天战报 中国选手8人晋级6人遭淘汰2人弃赛 预测事件类型: 竞赛行为-晋级
预测语句: 日本电车卡车相撞,车头部分脱轨并倾斜,现场起火浓烟滚滚 预测事件类型: 灾害/意外-车祸
预测语句: 截止到11日13:30 ,因台风致浙江32人死亡,16人失联。具体如下:永嘉县岩坦镇山早村23死9失联,乐清6死,临安区岛石镇银坑村3死4失联,临海市东塍镇王加山村3失联。 预测事件类型: 人生-失联|人生-死亡
预测语句: 定位B端应用,BeBop发布Quest专属版柔性VR手套 预测事件类型: 产品行为-发布
预测语句: 8月17日。凌晨3点20分左右,济南消防支队领秀城中队接到指挥中心调度命令,济南市中区中海环宇城往南方向发生车祸,有人员被困。 预测事件类型: 灾害/意外-车祸
预测语句: 注意!济南可能有雷电事故|英才学院14.9亿被收购|八里桥蔬菜市场今日拆除,未来将建新的商业综合体 预测事件类型: 财经/交易-出售/收购
预测语句: 昨天18:30,陕西宁强县胡家坝镇向家沟村三组发生山体坍塌,5人被埋。当晚,3人被救出,其中1人在医院抢救无效死亡,2人在送医途中死亡。今天凌晨,另外2人被发现,已无生命迹象。 预测事件类型: 人生-死亡|灾害/意外-坍/垮塌