
SUNSETTING torcnaudio-contrib
We made some progress in this repo and contributed to the original repo pytorch/audio which satisfied us. We happily stopped working here :) Please visit pytorch/audio for any issue/request!
.
.
.
.
.
.
.
.
.
.
(We keep the existing content as below
torchaudio-contrib
Goal: To propose audio processing Pytorch codes with nice and easy-to-use APIs and functionality.
Our motivation is:
- API design: Clear, readible names for class/functions/arguments, sensible default values, and shapes.
- Reference: librosa (audio and MIR on Numpy), kapre (audio on Keras), pytorch/audio (audio on Pytorch)
- Fast processing on GPU
- Methodology: Both layer and functional
- Layers (
nn.Module) for reusability and easier use - and identical implementation with
Functionals
- Layers (
- Simple installation
- Multi-channel support
Contribution
Making things quicker and open! We're -contrib repo, hence it's easy to enter but hard to graduate.
- Make a new Issue for a potential PR
- Until it's in a good shape,
- Make a PR with following the current conventions and unittest
- Review-merge.
- Based on it, make a PR to torch/audio
Discussion on how to contribute - #37
Current issues/future work
- Better module/sub-module hierarchy
- Complex number support
- More time-frequency representations
- Signal processing modules, e.g., vocoder
- Augmentation
API suggestions
Notes
- Audio signals can be multi-channel
STFT: short-time Fourier transform, outputing a complex-numbered representationSpectrogram: magnitudes of STFTMelspectrogram: mel-filterbank applied tospectrogram
Shapes
- audio signals:
(batch, channel, time)- E.g.,
STFTinput shape - Based on
torch.stftinput shape
- E.g.,
- 2D representations:
(batch, channel, freq, time)- E.g.,
STFToutput shape - Channel-first, following torch convention.
- Then,
(freq, time), followingtorch.stft
- E.g.,
Overview
STFT
class STFT(fft_len=2048, hop_len=None, frame_len=None, window=None, pad=0, pad_mode="reflect", **kwargs)
def stft(signal, fft_len, hop_len, window, pad=0, pad_mode="reflect", **kwargs)MelFilterbank
class MelFilterbank(num_bands=128, sample_rate=16000, min_freq=0.0, max_freq=None, num_bins=1025, htk=False)
def create_mel_filter(num_bands, sample_rate, min_freq, max_freq, num_bins, to_hertz, from_hertz)Spectrogram
def Spectrogram(fft_len=2048, hop_len=None, frame_len=None, window=None, pad=0, pad_mode="reflect", power=1., **kwargs)Creates an nn.Sequential:
>>> Sequential(
>>> (0): STFT(fft_len=2048, hop_len=512, frame_len=2048)
>>> (1): ComplexNorm(power=1.0)
)
Melspectrogram
def Melspectrogram(num_bands=128, sample_rate=16000, min_freq=0.0, max_freq=None, num_bins=None, htk=False, mel_filterbank=None, **kwargs)Creates an nn.Sequential:
>>> Sequential(
>>> (0): STFT(fft_len=2048, hop_len=512, frame_len=2048)
>>> (1): ComplexNorm(power=2.0)
>>> (2): ApplyFilterbank()
)
AmplitudeToDb/amplitude_to_db
class AmplitudeToDb(ref=1.0, amin=1e-7)
def amplitude_to_db(x, ref=1.0, amin=1e-7)Arguments names and the default value of ref follow librosa. The default value of amin however follows Keras's float32 Epsilon, which seems making sense.
DbToAmplitude/db_to_amplitude
class DbToAmplitude(ref=1.0)
def db_to_amplitude(x, ref=1.0)MuLawEncoding/mu_law_encoding
class MuLawEncoding(n_quantize=256)
def mu_law_encoding(x, n_quantize=256)MuLawDecoding/mu_law_decoding
class MuLawDecoding(n_quantize=256)
def mu_law_decoding(x_mu, n_quantize=256)A Big Issue - Remove SoX Dependency
We propose to remove the SoX dependency because:
- Many audio ML tasks don’t require the functionality included in Sox (filtering, cutting, effects)
- Many issues in torchaudio are related to the installation with respect to Sox. While this could be simplified by a conda build or a wheel, it will continue being difficult to maintain the repo.
- SOX doesn’t support MP4 containers, which makes it unusable for multi-stream audio
- Loading speed is good with torchaudio but e.g. for wav, its not faster than other libraries (including cast to torch tensor) -- as in the graph below. See more detailed benchmarks here.
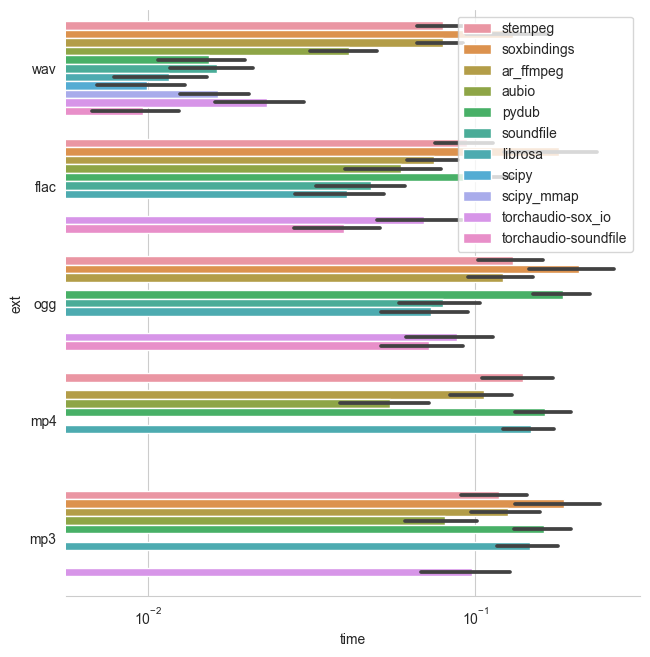
Proposal
Introduce I/O backends and move the functions that depend on _torch_sox to a backend_sox.py, which is not required to install. Additionally, we could then introduce more backends like scipy.io or pysoundfile. Each backend then imports the (optional) lib within the backend file and each backend includes a minimum spec such as:
import _torch_sox
def load(...)
# returns audio, rate
def save(...)
# write file
def info(...)
# returns metadata without reading the full file Backend proposals
scipy.ioorsoundfileas default for wav filesaubiooraudioreadfor mp3 and mp4
Installation
pip install -e .Importing
import torchaudio_contrib
Authors
Keunwoo Choi, Faro Stöter, Kiran Sanjeevan, Jan Schlüter