
WaterDrop
![]()

A gem to send messages to Kafka easily with an extra validation layer. It is a part of the Karafka ecosystem.
It:
- Is thread-safe
- Supports sync producing
- Supports async producing
- Supports buffering
- Supports producing messages to multiple clusters
- Supports multiple delivery policies
- Works with Kafka
1.0+and Ruby2.7+
Table of contents
Installation
Note: If you want to both produce and consume messages, please use Karafka. It integrates WaterDrop automatically.
Add this to your Gemfile:
gem 'waterdrop'and run
bundle install
Setup
WaterDrop is a complex tool that contains multiple configuration options. To keep everything organized, all the configuration options were divided into two groups:
- WaterDrop options - options directly related to WaterDrop and its components
- Kafka driver options - options related to
rdkafka
To apply all those configuration options, you need to create a producer instance and use the #setup method:
producer = WaterDrop::Producer.new
producer.setup do |config|
config.deliver = true
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'request.required.acks': 1
}
endor you can do the same while initializing the producer:
producer = WaterDrop::Producer.new do |config|
config.deliver = true
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'request.required.acks': 1
}
endWaterDrop configuration options
Some of the options are:
| Option | Description |
|---|---|
id |
id of the producer for instrumentation and logging |
logger |
Logger that we want to use |
deliver |
Should we send messages to Kafka or just fake the delivery |
max_wait_timeout |
Waits that long for the delivery report or raises an error |
wait_timeout |
Waits that long before re-check of delivery report availability |
wait_on_queue_full |
Should be wait on queue full or raise an error when that happens |
wait_backoff_on_queue_full |
Waits that long before retry when queue is full |
wait_timeout_on_queue_full |
If back-offs and attempts that that much time, error won't be retried more |
Full list of the root configuration options is available here.
Kafka configuration options
You can create producers with different kafka settings. Documentation of the available configuration options is available on https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md.
Usage
Basic usage
To send Kafka messages, just create a producer and use it:
producer = WaterDrop::Producer.new
producer.setup do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
producer.produce_sync(topic: 'my-topic', payload: 'my message')
# or for async
producer.produce_async(topic: 'my-topic', payload: 'my message')
# or in batches
producer.produce_many_sync(
[
{ topic: 'my-topic', payload: 'my message'},
{ topic: 'my-topic', payload: 'my message'}
]
)
# both sync and async
producer.produce_many_async(
[
{ topic: 'my-topic', payload: 'my message'},
{ topic: 'my-topic', payload: 'my message'}
]
)
# Don't forget to close the producer once you're done to flush the internal buffers, etc
producer.closeEach message that you want to publish, will have its value checked.
Here are all the things you can provide in the message hash:
| Option | Required | Value type | Description |
|---|---|---|---|
topic |
true | String | The Kafka topic that should be written to |
payload |
true | String | Data you want to send to Kafka |
key |
false | String | The key that should be set in the Kafka message |
partition |
false | Integer | A specific partition number that should be written to |
partition_key |
false | String | Key to indicate the destination partition of the message |
timestamp |
false | Time, Integer | The timestamp that should be set on the message |
headers |
false | Hash | Headers for the message |
Keep in mind, that message you want to send should be either binary or stringified (to_s, to_json, etc).
Using WaterDrop across the application and with Ruby on Rails
If you plan to both produce and consume messages using Kafka, you should install and use Karafka. It integrates automatically with Ruby on Rails applications and auto-configures WaterDrop producer to make it accessible via Karafka#producer method:
event = Events.last
Karafka.producer.produce_async(topic: 'events', payload: event.to_json)If you want to only produce messages from within your application without consuming with Karafka, since WaterDrop is thread-safe you can create a single instance in an initializer like so:
KAFKA_PRODUCER = WaterDrop::Producer.new
KAFKA_PRODUCER.setup do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
# And just dispatch messages
KAFKA_PRODUCER.produce_sync(topic: 'my-topic', payload: 'my message')Using WaterDrop with a connection-pool
While WaterDrop is thread-safe, there is no problem in using it with a connection pool inside high-intensity applications. The only thing worth keeping in mind, is that WaterDrop instances should be shutdown before the application is closed.
KAFKA_PRODUCERS_CP = ConnectionPool.new do
WaterDrop::Producer.new do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
end
KAFKA_PRODUCERS_CP.with do |producer|
producer.produce_async(topic: 'my-topic', payload: 'my message')
end
KAFKA_PRODUCERS_CP.shutdown { |producer| producer.close }Buffering
WaterDrop producers support buffering messages in their internal buffers and on the rdkafka level via queue.buffering.* set of settings.
This means that depending on your use case, you can achieve both granular buffering and flushing control when needed with context awareness and periodic and size-based flushing functionalities.
Idempotence
When idempotence is enabled, the producer will ensure that messages are successfully produced exactly once and in the original production order.
To enable idempotence, you need to set the enable.idempotence kafka scope setting to true:
WaterDrop::Producer.new do |config|
config.deliver = true
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'enable.idempotence': true
}
endThe following Kafka configuration properties are adjusted automatically (if not modified by the user) when idempotence is enabled:
max.in.flight.requests.per.connectionset to5retriesset to2147483647acksset toall
The idempotent producer ensures that messages are always delivered in the correct order and without duplicates. In other words, when an idempotent producer sends a message, the messaging system ensures that the message is only delivered once to the message broker and subsequently to the consumers, even if the producer tries to send the message multiple times.
Compression
WaterDrop supports following compression types:
gzipzstdlz4snappy
To use compression, set kafka scope compression.codec setting. You can also optionally indicate the compression.level:
producer = WaterDrop::Producer.new
producer.setup do |config|
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'compression.codec': 'gzip',
'compression.level': 6
}
endNote: In order to use zstd, you need to install libzstd-dev:
apt-get install -y libzstd-devUsing WaterDrop to buffer messages based on the application logic
producer = WaterDrop::Producer.new
producer.setup do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
# Simulating some events states of a transaction - notice, that the messages will be flushed to
# kafka only upon arrival of the `finished` state.
%w[
started
processed
finished
].each do |state|
producer.buffer(topic: 'events', payload: state)
puts "The messages buffer size #{producer.messages.size}"
producer.flush_sync if state == 'finished'
puts "The messages buffer size #{producer.messages.size}"
end
producer.closeUsing WaterDrop with rdkafka buffers to achieve periodic auto-flushing
producer = WaterDrop::Producer.new
producer.setup do |config|
config.kafka = {
'bootstrap.servers': 'localhost:9092',
# Accumulate messages for at most 10 seconds
'queue.buffering.max.ms': 10_000
}
end
# WaterDrop will flush messages minimum once every 10 seconds
30.times do |i|
producer.produce_async(topic: 'events', payload: i.to_s)
sleep(1)
end
producer.closeInstrumentation
Each of the producers after the #setup is done, has a custom monitor to which you can subscribe.
producer = WaterDrop::Producer.new
producer.setup do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
producer.monitor.subscribe('message.produced_async') do |event|
puts "A message was produced to '#{event[:message][:topic]}' topic!"
end
producer.produce_async(topic: 'events', payload: 'data')
producer.closeSee the WaterDrop::Instrumentation::Notifications::EVENTS for the list of all the supported events.
Karafka Web-UI
Karafka Web UI is a user interface for the Karafka framework. The Web UI provides a convenient way for monitor all producers related errors out of the box.
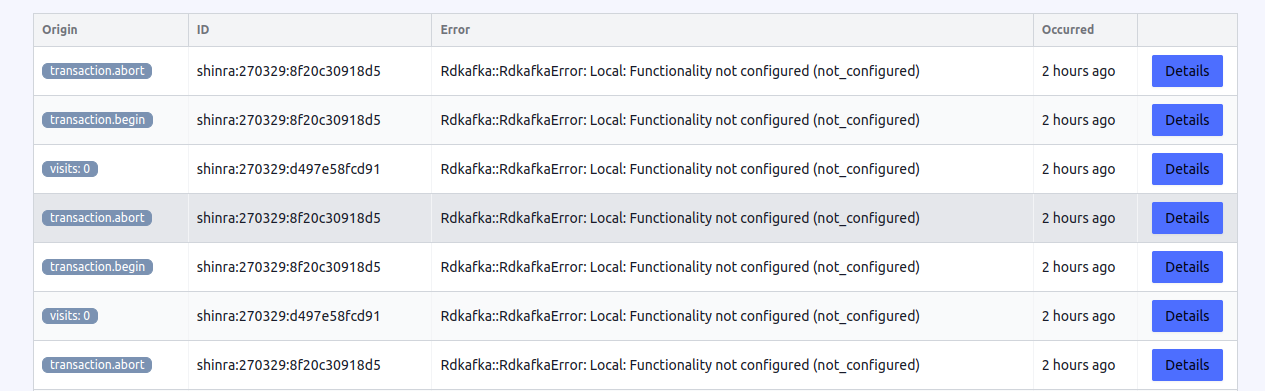
Usage statistics
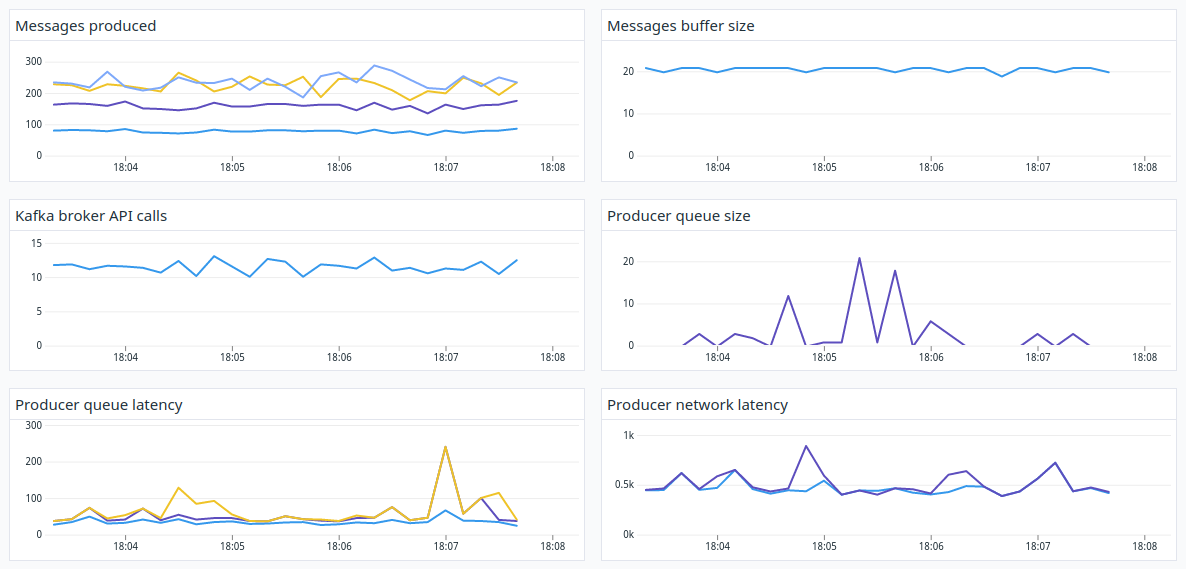
WaterDrop is configured to emit internal librdkafka metrics every five seconds. You can change this by setting the kafka statistics.interval.ms configuration property to a value greater of equal 0. Emitted statistics are available after subscribing to the statistics.emitted publisher event. If set to 0, metrics will not be published.
The statistics include all of the metrics from librdkafka (complete list here) as well as the diff of those against the previously emitted values.
For several attributes like txmsgs, librdkafka publishes only the totals. In order to make it easier to track the progress (for example number of messages sent between statistics emitted events), WaterDrop diffs all the numeric values against previously available numbers. All of those metrics are available under the same key as the metric but with additional _d postfix:
producer = WaterDrop::Producer.new do |config|
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'statistics.interval.ms': 2_000 # emit statistics every 2 seconds
}
end
producer.monitor.subscribe('statistics.emitted') do |event|
sum = event[:statistics]['txmsgs']
diff = event[:statistics]['txmsgs_d']
p "Sent messages: #{sum}"
p "Messages sent from last statistics report: #{diff}"
end
sleep(2)
# Sent messages: 0
# Messages sent from last statistics report: 0
20.times { producer.produce_async(topic: 'events', payload: 'data') }
# Sent messages: 20
# Messages sent from last statistics report: 20
sleep(2)
20.times { producer.produce_async(topic: 'events', payload: 'data') }
# Sent messages: 40
# Messages sent from last statistics report: 20
sleep(2)
# Sent messages: 40
# Messages sent from last statistics report: 0
producer.closeNote: The metrics returned may not be completely consistent between brokers, toppars and totals, due to the internal asynchronous nature of librdkafka. E.g., the top level tx total may be less than the sum of the broker tx values which it represents.
Error notifications
WaterDrop allows you to listen to all errors that occur while producing messages and in its internal background threads. Things like reconnecting to Kafka upon network errors and others unrelated to publishing messages are all available under error.occurred notification key. You can subscribe to this event to ensure your setup is healthy and without any problems that would otherwise go unnoticed as long as messages are delivered.
producer = WaterDrop::Producer.new do |config|
# Note invalid connection port...
config.kafka = { 'bootstrap.servers': 'localhost:9090' }
end
producer.monitor.subscribe('error.occurred') do |event|
error = event[:error]
p "WaterDrop error occurred: #{error}"
end
# Run this code without Kafka cluster
loop do
producer.produce_async(topic: 'events', payload: 'data')
sleep(1)
end
# After you stop your Kafka cluster, you will see a lot of those:
#
# WaterDrop error occurred: Local: Broker transport failure (transport)
#
# WaterDrop error occurred: Local: Broker transport failure (transport)Note: error.occurred will also include any errors originating from librdkafka for synchronous operations, including those that are raised back to the end user.
Acknowledgment notifications
WaterDrop allows you to listen to Kafka messages' acknowledgment events. This will enable you to monitor deliveries of messages from WaterDrop even when using asynchronous dispatch methods.
That way, you can make sure, that dispatched messages are acknowledged by Kafka.
producer = WaterDrop::Producer.new do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
producer.monitor.subscribe('message.acknowledged') do |event|
producer_id = event[:producer_id]
offset = event[:offset]
p "WaterDrop [#{producer_id}] delivered message with offset: #{offset}"
end
loop do
producer.produce_async(topic: 'events', payload: 'data')
sleep(1)
end
# WaterDrop [dd8236fff672] delivered message with offset: 32
# WaterDrop [dd8236fff672] delivered message with offset: 33
# WaterDrop [dd8236fff672] delivered message with offset: 34Datadog and StatsD integration
WaterDrop comes with (optional) full Datadog and StatsD integration that you can use. To use it:
# require datadog/statsd and the listener as it is not loaded by default
require 'datadog/statsd'
require 'waterdrop/instrumentation/vendors/datadog/metrics_listener'
# initialize your producer with statistics.interval.ms enabled so the metrics are published
producer = WaterDrop::Producer.new do |config|
config.deliver = true
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'statistics.interval.ms': 1_000
}
end
# initialize the listener with statsd client
listener = ::WaterDrop::Instrumentation::Vendors::Datadog::MetricsListener.new do |config|
config.client = Datadog::Statsd.new('localhost', 8125)
# Publish host as a tag alongside the rest of tags
config.default_tags = ["host:#{Socket.gethostname}"]
end
# Subscribe with your listener to your producer and you should be ready to go!
producer.monitor.subscribe(listener)You can also find here a ready to import DataDog dashboard configuration file that you can use to monitor all of your producers.
Forking and potential memory problems
If you work with forked processes, make sure you don't use the producer before the fork. You can easily configure the producer and then fork and use it.
To tackle this obstacle related to rdkafka, WaterDrop adds finalizer to each of the producers to close the rdkafka client before the Ruby process is shutdown. Due to the nature of the finalizers, this implementation prevents producers from being GCed (except upon VM shutdown) and can cause memory leaks if you don't use persistent/long-lived producers in a long-running process or if you don't use the #close method of a producer when it is no longer needed. Creating a producer instance for each message is anyhow a rather bad idea, so we recommend not to.
Middleware
WaterDrop supports injecting middleware similar to Rack.
Middleware can be used to provide extra functionalities like auto-serialization of data or any other modifications of messages before their validation and dispatch.
Each middleware accepts the message hash as input and expects a message hash as a result.
There are two methods to register middlewares:
#prepend- registers middleware as the first in the order of execution#append- registers middleware as the last in the order of execution
Below you can find an example middleware that converts the incoming payload into a JSON string by running #to_json automatically:
class AutoMapper
def call(message)
message[:payload] = message[:payload].to_json
message
end
end
# Register middleware
producer.middleware.append(AutoMapper.new)
# Dispatch without manual casting
producer.produce_async(topic: 'users', payload: user)Note: It is up to the end user to decide whether to modify the provided message or deep copy it and update the newly created one.
Note on contributions
First, thank you for considering contributing to the Karafka ecosystem! It's people like you that make the open source community such a great community!
Each pull request must pass all the RSpec specs, integration tests and meet our quality requirements.
Fork it, update and wait for the Github Actions results.