
迷你型类Linux操作系统



目录
项目介绍
此项目的灵感来源于 MIT 6.828 的课程 由于本人水平有限,又由于只想写一个玩具操作系统,所以部分代码可能不是很规范,注释也是很少,请大家谅解
此操作系统在重定向和管道功能上有点小bug,由于时间原因我就不debug了
在终端输入
git clone https://github.com/goldknife6/fuckOS
cd fuckOS
然后在终端输入 make qemu
等内核编译完之后就开始在虚拟机里运行内核了
if occur anything problems likes undefined reference to __udivdi3
please sudo apt-get install gcc-4.8-multilib
然后让我们运行一下小程序吧
#include <lib.h>
#include <string.h>
#include <stdio.h>
#include <fcntl.h>
#define DEPTH 10
void forktree(const char *cur);
void forkchild(const char *cur, char branch)
{
char nxt[DEPTH+1];
int i;
if (strlen(cur) >= DEPTH)
return;
snprintf(nxt, DEPTH+1, "%s%c", cur, branch);
if ((i = fork()) == 0) {
forktree(nxt);
exit();
} else if (i < 0)
printf("forktree fork error! pid :%d err:%d\n",getpid(),i);
}
void forktree(const char *cur)
{
printf("%08d: I am '%s'\n", getpid(), cur);
forkchild(cur, '0');
forkchild(cur, '1');
}
int main(int argc, char **argv)
{
//open("/dev/tty",O_RDWR,0);
forktree("");
//printf("forktree over!%d\n",getpid());
return 0;
}
开发环境:
Ubuntu14.04+ GCC version 5.2.1
测试环境:
QEMU emulator version 2.3.0 ThinkPad E431
具体实现与特点:
1、可在真机上运行
2、实现buddy分页系统,slub内存分配系统
3、实现VFS(虚拟文件系统)
4、实现各种库函数(eg. malloc)
5、支持SMP,也就是多处理器
使用方法:
下载源码后,在终端输入make qemu,会自动完成内核的编译,然后内核就会运行在qemu虚拟机里
ELF文件格式介绍
ELF全称为Executable and Linking Format,在《深入理解计算机系统》的第七章里面说的很明白了,说白了就是一种目标文件格式。详细内容请自行参考Executable and Linking Format Specification
目标文件有三种格式:
- 可重定位目标文件
这是由汇编器汇编生成的 .o 文件。链接器拿一个或一些可重定位目标文件(Relocatable object files) 作为输入,经链接处理后,生成一个可执行的目标文件 (Executable file) 或者一个可被共享的对象文件(Shared object file)。
- 可执行目标文件(Executable file)
包含二进制代码和数据,可以直接加载进内存并执行的一种文件。文本编辑器vi、调式用的工具gdb、播放mp3歌曲的软件mplayer等等都是Executable object file。
- 可被共享的对象文件(Shared object file)
一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态地加载到内存中,这些就是所谓的动态库文件,也即 .so
zz@zz-pc:~/fuckOS$ readelf -a kern
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0xc0100000
Start of program headers: 52 (bytes into file)
Start of section headers: 1112092 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 3
Size of section headers: 40 (bytes)
Number of section headers: 11
Section header string table index: 8
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS c0100000 001000 009ce1 00 AX 0 0 16
[ 2] .rodata PROGBITS c0109d00 00ad00 0015c0 00 A 0 0 32
[ 3] .stab PROGBITS c010b2c0 00c2c0 01b511 0c A 4 0 4
[ 4] .stabstr STRTAB c01267d1 0277d1 00e68e 00 A 0 0 1
[ 5] .data PROGBITS c0135000 036000 0d3a83 00 WA 0 0 4096
[ 6] .bss NOBITS c0209000 109a83 13a164 00 WA 0 0 4096
[ 7] .comment PROGBITS 00000000 109a83 000056 01 MS 0 0 1
[ 8] .shstrtab STRTAB 00000000 109ad9 00004c 00 0 0 1
[ 9] .symtab SYMTAB 00000000 109b28 0034f0 10 10 192 4
[10] .strtab STRTAB 00000000 10d018 002802 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
There are no section groups in this file.
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x001000 0xc0100000 0x00100000 0x34e5f 0x34e5f R E 0x1000
LOAD 0x036000 0xc0135000 0x00135000 0xd3a83 0x20e164 RW 0x1000
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RWE 0x10
上面就是内核的ELF文件头的内容,其中 Program Headers 中的 LOAD 类型的节会被加载到内存中
加载器介绍
此操作系统并没有实现加载器,而是使用的现成的Grub加载器。为了使内核可以被Grub加载到内存,内核的前8192个字节内必须包含多重引导头部
其实很简单,只要在内核入口文件entry.S前加上几行代码就可以了,这些字段和多重引导头部的详细定义请参考Multiboot规范
.text
.globl start, _start
start:
_start:
jmp multiboot_entry
.balign MULTIBOOT_HEADER_ALIGN
_header_start:
.long MULTIBOOT2_HEADER_MAGIC
.long MULTIBOOT_ARCHITECTURE_I386
.long _header_end - _header_start
.long CHECKSUM
.balign MULTIBOOT_TAG_ALIGN
.word MULTIBOOT_HEADER_TAG_END
.word 0
.long 8
_header_end:
有了这个头部,Grub就会把内核加载到由ELF文件格式中PhysAddr指定的物理内存中,然后Grub就会把控制权交给内核的入口点,也就是start ,0x00100000,是物理地址而不室虚拟地址,之后就开始运行内核了。PhysAddr的值是由链接脚本设定的,后面我会讲。
链接脚本介绍
链接脚本介绍
制作U盘启动
我们需要grub2程序,使用前先检查是否是最新的版本 插入U盘,U盘最少需要一个分区,分区容量最好小一点,20MB就够,不然速度会很慢。 假设U盘设备为/dev/sdb,其中某个分区挂载到了/mnt 执行下面的命令
sudo grub-install --root-directory=/mnt --no-floppy /dev/sdb
等待完成就OK
然后把grub.cfg 考到/mnt/boot/grub文件加下,然后把内核文件kern拷到/mnt/boot下就可以了,然后再用fdisk把/dev/sdb1设置成启动分区
内核
内存管理
内存管理大至分为两个部分
第一个部分是内核的物理内存分配器,内核中所有核心数据结构都是由物理内存分配器分配和释放的。 此内核的物理内存分配器又分为两个部分,第一部分是Buddy分页系统,第二部分是Slub内存分配系统,Slub内存分配系统是建立在第一部之上的。
第二个部分就是虚拟内存的管理,我们需要把内核和用户级程序的虚拟内存映射到物理内存上
物理页框
本操作系统的物理地址被分为两个区域,一个称为normal zone,一个称为high zone。normal zone管理0x0~0x4000000之间的物理页面,high zone管理0x4000000~16GB之间的物理页面。 操作系统必须保持跟踪哪一个物理页是空闲的,哪一个物理页是正在使用的。关于物理页的信息是由叫做struct page的结构体来维护的。
struct page *mempage;
这个变量用来管理struct page数组。 操作系统首先先探测电脑的物理内存布局,之后根据物理内存是否可用对物理页进行标记。
页表
先看一下二级页表的图
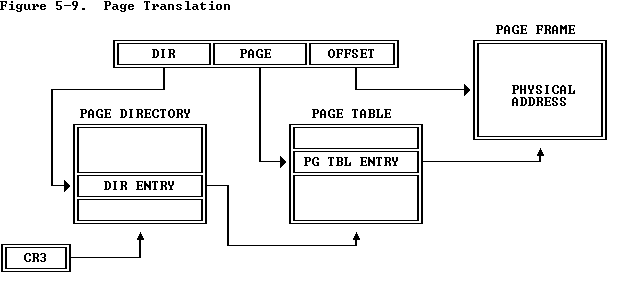
操作系统理论书籍都描述了页表转换是如何进行的,在此我就不描述了。 对页表进行操作的函数为以下几个函数:
涉及的文件:
kernel/mm/pages.c include/mm/pages.h include/mm/pgtable-3level.h include/mm/pgtable-2level.h
pte_t *page_walk(pgd_t *pgdp,viraddr_t address,bool create) //对全局页目录进行遍历,返回对应地址的页表实体
int page_insert(pgd_t *pgd, struct page *page,viraddr_t va, uint32_t perm)//对某个虚拟地址插入一个物理页
void page_remove(pgd_t *pgd, viraddr_t va);//删除某虚拟地址上的物理页
struct page* page_lookup(pgd_t *pgd,viraddr_t va, pte_t **pte_store)
void page_decref(struct page* page)//减少引用计数
内核地址空间
操作系统的地址空间划分为了两个部分,0xC0000000~0xFFFFFFFF为内核的地址空间,0x0~0xC0000000为用户进程的地址空间。关于地址空间的一些常熟定义在include/mm/layout.h 中。
/*
* Virtual memory map: Permissions
* kernel/user
*
* 4 Gig ------------------------------------------------>0xFFFFFFFF
* PTSIZE
* KERNEL_LIMIT/KERNEL_MMIO_LIMIT------------------------>0xFFC00000
* PTSIZE
* KERNEL_MMIO------------------------------------------->0xFF800000
* Gap. PTSIZE
* ------------------------------------------------------>0xFF400000
* PTSIZE
* KERNEL_VIDEO & KERNEL_TEMP---------------------------->0xFF000000
*
*
* KERNEL_STACK_TOP-------------------------------------->0xF0800000
*
* CPU Kernel Stack PAGE_SIZE
*
* Invalid Memory (*) PAGE_SIZE
*
*
* KERNEL_NORMAL/KERNEL_STACK---------------------------->0xF0000000
* RW/--
* KERNEL_BASE_ADDR-------------------------------------->0xC0000000
* 2*PTSIZE
* USER_STACKTOP/USER_TEMPBOTT--------------------------->0xBF800000 .
* . PTSIZE
* USER_STACKBOTT---------------------------------------->0xBF400000
*
*
* USER_UNNAME_ZONE-------------------------------------->0x40000000
*
*
* USER_BRK_ZONE----------------------------------------->0x10000000
*/
内核页目录的映射代码在kernel/mm/bootmm.c文件中
static void bootmm_init()
{
...
//分配内核页目录
kpgd = alloc_bootmm_pages(1);
memset(kpgd,0,PAGE_SIZE);
//映射内核页目录 0xc0000000 ~ 0xf0000000 = 0x00000000 ~ 0x30000000
boot_map_region(kpgd, KERNEL_BASE_ADDR, NORMAL_ADDR, 0, _PAGE_RW | _PAGE_PRESENT);
//映射内核VAG映射区
boot_map_region(kpgd, KERNEL_VIDEO, PT_SIZE, 0xb8000, _PAGE_RW | _PAGE_PRESENT);
....
//映射内核栈区域
for(i = 0;i < CPUNUMS; i++) {
boot_map_region(kpgd, KERNEL_STACK_TOP -KERNEL_STKSIZE - (KERNEL_STKSIZE + PAGE_SIZE) * i,
KERNEL_STKSIZE, v2p(percpu_kstacks[i]),_PAGE_PRESENT|_PAGE_RW);
}
lcr3(pgd2p(kpgd));
.....
}因为用户空间和内核空间都出现在进程的地址空间中,我们在页表中使用x86的权限位从而限制用户进程访问内核空间。用户进程对高于0xc0000000的地址是没有访问权限的。
Buddy系统
涉及的文件为kernel/mm/zone include/mm/mmzone.h
此算法的详细内容请参考《深入理解Linux内核》或自行百度。
Buddy系统管理内存的单位是页,也就是4K为一个单位。Buddy系统会用struct page *mempage这个已经初始化好了的物理页描述符数组来进行buddy系统的初始化。
struct page* alloc_buddy(struct zone_struct *,uint8_t); 物理页分配函数 一次分配2的0~10次方个页,也就是4KB~4BM
void free_buddy(struct zone_struct *,struct page*,uint8_t);释放函数
void zone_init();初始化函数Slub内存分配系统
涉及的文件为kernel/mm/slab.c include/slab.h
void slab_init();初始化函数
void* kmalloc(size_t size);内存分配函数
void kfree(void* );释放函数进程环境
进程的管理
进程描述符
struct task_struct
{
struct mm_struct* mm; //进程的内存描述符
struct files_struct* files;//关于进程文件的结构体
struct fs_struct* fs;
struct frame frame; //进程切换时保存的上下文
pgd_t* task_pgd;//进程的页表
pid_t pid; //进程ID
pid_t ppid; //父进程ID
.....
int32_t timeslice;//进程所剩的时间片
.....
int pwait;
};此结构体标识了一个进程,每个字段为进程的一个基本信息。
kernel/task.c
static int load_icode(struct task_struct *, uint8_t *);
static int region_alloc(struct task_struct *, viraddr_t, size_t ,int );
static int task_alloc(struct task_struct **, pid_t);
struct task_struct* task_pidmap[PID_MAX_DEFAULT];
static int alloc_files_struct(struct task_struct *);以上几个函数就是创建进程的基本函数,这些函数只用于静态创建init进程。在编译内核的时候我们以及把用户程序件链接进了内核,load_icode这个函数用于把相应的用户复制进struct task_struct结构体中从而创建了进程init。
进程地址空间
进程的内存描述符,详细内容请参考《深入理解Linux内核》第九章
struct mm_struct
{
struct vm_area_struct* mmap;//进程的线性地址空间的链表
struct rb_root mm_rb;
pgd_t* mm_pgd;
viraddr_t free_area_cache;
viraddr_t start_code;//起始代码段
viraddr_t end_code;
viraddr_t start_data;//起始数据段段
viraddr_t end_data;
viraddr_t start_brk;//起始堆段
viraddr_t end_brk;
viraddr_t start_stack;//栈段
int mmap_count;
atomic_t mm_count;
spinlock_t page_table_lock;
};
struct vm_area_struct
{
struct mm_struct* vm_mm;
struct vm_area_struct* vm_next;
struct rb_node vm_rb;
viraddr_t vm_start;//线性区起始地址
viraddr_t vm_end;
uint32_t vm_flags;
};以上结构体就是用来描述一个进程的地址空间的。 比如,当进程需要扩展堆段的时候就会调用系统函数brk(); 之后内核就会增加viraddr_t end_brk;这个值;
中断与异常
参考 Chapter 9, Exceptions and Interrupts
中断描述符表
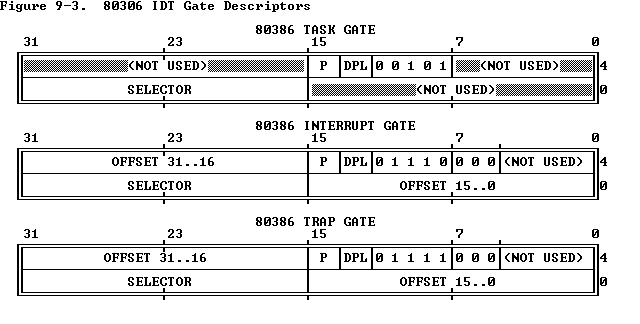
任务状态段
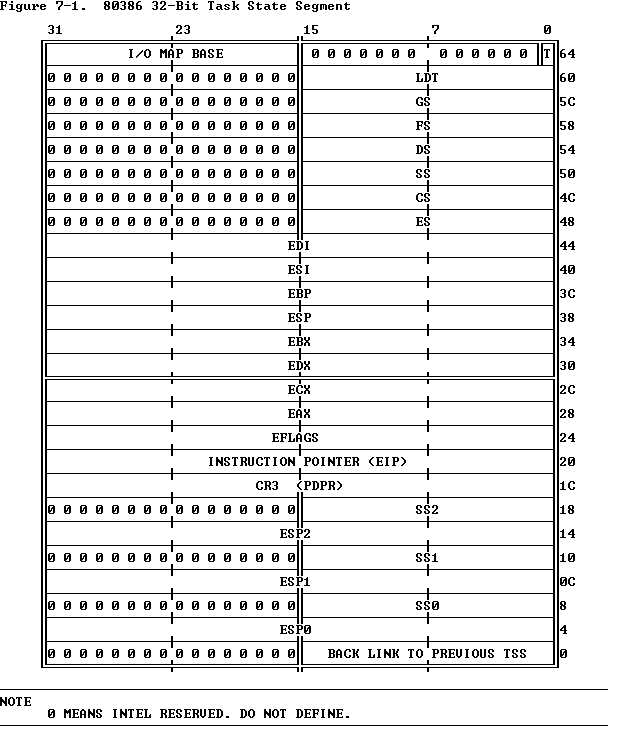
中断与异常都是受保护的控制转移,在英特尔的术语中,中断是由异步事件所导致的,比如IO事件。而异常是由同步事件所导致的,比如执行了某条命令(int),为了使中断与异常的控制转移在内核的控制之下,我们需要配置中断描述符表和任务状态段。
x86最多可以有256个中断和异常,有硬件设备使用的(时钟中断为32号),有异常条件使用的(比如页故障是14号),也有用户自定义的(比如系统调用就是使用中断号128),所以说我们要为每一个号分配一个地址,这样当中断或异常发生的时候控制路径就会转移到制定的地点。在中断或异常发生之前,处理器需要一个地方来存放寄存器的状态(这就是操作系统理论中进程的上下文),这样执行完异常处理器之后就可以返回到原来发生中断或异常的地方了。这个存放进程的上下文的地方需要保护起来,不然进程就可能随意更改从而导致内核奔溃。
所有中断和异常由void trap(struct frame *tf)这个函数接管。
配置中断描述符表和任务状态段涉及文件kernel/trap/trapentry.S 和kernel/trap/trap.c
//配置任务状态段
void trap_init_percpu()
{
extern struct seg_descriptor gdt[CPUNUMS + 5];
extern int ncpu;
uint32_t cid = get_cpuid();
struct taskstate *pts = &(thiscpu->cpu_ts);
pts->ts_ss0 = _KERNEL_DS_;
pts->ts_esp0 = KERNEL_STACK_TOP - (KERNEL_STKSIZE + PAGE_SIZE) * cid;
gdt[(_TSS0_ >> 3) + cid] = set_seg(STS_T32A, (uint32_t) (pts), sizeof(struct taskstate), 0);
gdt[(_TSS0_ >> 3) + cid].s = 0;
ltr(_TSS0_ + cid * sizeof(struct seg_descriptor));
lidt(&idt_pd);
}
//配置中断描述符表
void trap_init()
{
int i;
extern uint32_t trap_handlers[];
for(i = 0;i < 255; i++) {
setgate(idt[i], 0, _KERNEL_CS_, trap_handlers[i], 0);
}
setgate(idt[T_SYSCALL], 0, _KERNEL_CS_, trap_handlers[T_SYSCALL], 3);
trap_init_percpu();
}页故障
内存保护是确保进程隔离的关键,内核的缺页处理器要区分两种情况:1、由编程错误引起的异常,程序访问了不属于进程地址空间的地址。2、进程访问了属于进程地址空间但是还没有分配物理页面的地址
第一种情况是非法的,要杀死进程。第二种情况是合法的,要给相应的地址分配物理内存。
当刚创建进程的时候内核只给进程分配了一个页的栈,当经常使用了超出4KB的栈的范围的时候,会出现一个缺页异常,然后就会进入缺页处理程序
kernel/trap/page_fault.c
void page_fault_handler(struct frame *tf)
{
viraddr_t va;
struct vm_area_struct *vma;
pte_t *pte;
va = rcr2();
vma = find_vma(curtask->mm, va);
if (!vma || vma->vm_start > va)
goto exit;
pte = page_walk(curtask->task_pgd,va,true);
if(!pte)
goto exit;
handle_pte_fault(curtask->mm, vma, va, pte, tf->tf_err);
return;
exit:
exit(curtask);
schedule();
}这个程序会判断导致缺页异常的地址是否属于进程的地址空间,如果不是就退出进程,如果是就为进程分配物理页。
系统调用
进程使用ini指令来进行系统调用。尤其是使用128号中断。用寄存器来传递参数。
kernel/trap/syscall.c
//一下为实现的系统服务例程
static int sys_exit(pid_t);
static pid_t sys_clone(int ,int (*)(void*));
static pid_t sys_getpid();
static void sys_cputs(const char *,size_t );
static viraddr_t sys_brk(viraddr_t);
static int sys_read(uint32_t,int8_t*,int32_t);
static int sys_open(char * ,int ,int, int);
static int sys_create(char * ,int,int);
static int sys_mkdir(char *filename, int len,int mode);
static int sys_write(int, char *,int);
static int sys_dup(int);
static int sys_dup2(int,int);
static void sys_close(int);
static int sys_pipe(int fd[2],int flags);
static int sys_wait(pid_t pid);
static int sys_execve(char *filename,char ** argv);
static int sys_fdtype(int);fork与写时复制
//文件kernel/syscall/fork.c
extern int alloc_pidmap();
extern void free_pidmap(pid_t);
extern int exit_task(struct task_struct *);
extern int exit_mm(struct mm_struct *);
static int copy_files(struct task_struct *task,int flags);
static int copy_task(struct task_struct *,struct task_struct *);
static int alloc_task(struct task_struct **,pid_t);
static int task_set_vm(int,struct task_struct *);以上就是fork系统调用的实现了。其实根究函数的名字就可以判断这些函数的功能,比如copy_files其实就是复制父进程的文联描述符啦,copy_task就是复制父进程的地址空间了,alloc_pidmap()是分配一个pid啦。
写入时复制(Copy-on-write)是一个被使用在程式设计领域的最佳化策略。其基础的观念是,如果有多个呼叫者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个呼叫者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到,这过程对其他的呼叫只都是通透的(transparently)。此作法主要的优点是如果呼叫者并没有修改该资源,就不会有副本(private copy)被建立。
内核实际进行fork的时候并不会真正复制一个副本给子进程,实际上子进程是与父进程共享相同的地址空间的。但是父进程与子进程的地址空间的权限变成了只读的。无论父进程还是子进程何时试图写一个共享的页帧,就产生一个异常,这时内核就把这个页复制到一个新的页帧中并标记为可写。原来的页帧仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页帧的唯一属主,如果是,就把这个页帧标记为对这个进程是可写的。这部分的代码其实由页故障处理器完成的。
malloc的实现
//fuckOS/lib/malloc.c
static struct malloc_chunk *find_malloc(uint32_t);
static struct malloc_chunk *extend_malloc(uint32_t);
static void split_malloc(struct malloc_chunk *,uint32_t);
static void merger_malloc(struct malloc_chunk *);malloc的实现其实挺简单,利用sbrk这个系统调用进行堆的扩展,然后利用隐式空闲链表来管理内存。详细内容请参考《深入理解计算机系统》第9章第9节
抢占式多任务
多处理器支持
多处理器支持需要涉及些硬件和协议,在多处理器系统中,每个CPU都有一个LAPIC(本地高级可编程中断控制器),LAPIC用于为CPU递送中断的,LAPIC也为每个CUP提供的一个唯一的标识。电脑加电的时候,先启动一个CPU,叫做BSP( bootstrap processor ),等内核完成了相应的初始化,由BSP启动其他的CPU,叫做AP(application processors)。BSP启动AP的时候需要发IPI(Inter-Processor Interrupts)给AP,这就用到LAPIC了。详细内容请参考《x86/x64体系探索及编程》的第十八章。
//kernel/trap/lapic.c
void ap_startup();
void lapic_init()再启动AP之前,我们还需要为AP处理器建立内核栈。之前已经给出代码kernel/mm/bootmm bootmm_init()
进程调度
此操作系统实现的只是简单的轮转调度每次时钟中断发生的时候会调用schedule_tick()减少进程的时间片。
//kernel/trap/irq_timer.c
void timer_handler(struct frame *tf)
{
lapic_eoi();
time_tick();
schedule_tick();//减少进程的时间片
}每次中断返回时会检查时间片是否还有剩余,如果没有就进行切换,否则什么也不做。
void trap(struct frame *tf)
{
...
schedule();//调度
}虚拟文件系统
虚拟文件系统
进程间通信
进程间通信
A mini operating system.
You need bochs or qemu to boot this os.
type make on the terminal to compile the kernel and type make boch or make qemu to start kernel up.
You need sudo apt-get install xorriso.