
SportsMOT
The official repo of the ICCV 2023 paper SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes

🏀🏐⚽
News
- 🔥 Code for our MixSort has been released.
- 🔥 Our paper SportsMOT is accepted to ICCV2023. Code for the proposed method MixSort will be released in a few days.
- SportsMOT test set has been made public on Codalab. Welcome!
- Notifications and reminders for DeeperAction@ECCV-2022 competition.[Finished]
- SportsMOT is used for DeeperAction@ECCV-2022.[Finished]
![]()
- SportsMOT has been shared to community via Paperwithcode
Overview
Demos

📹 Jigsaw demo

📹 Basketball Demo(NBA)

📹 Volleyball Demo(London 2012)
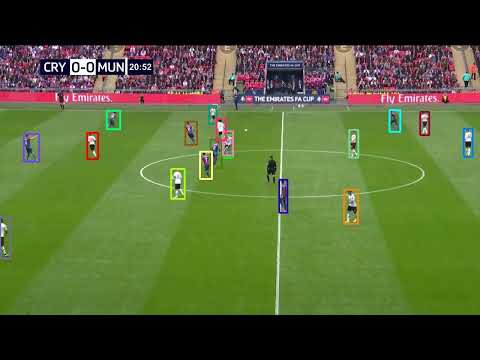
📹 Football Demo(FA Cup)
Data Collection
Diverse Sources
We provide 240 sports video clips of 3 categories (i.e., basketball, football and volleyball), where are collected from Olymplic Games, NCAA Championship, and NBA on YouTube. Only the search results with 720P resolution, 25 FPS, and official recording are downloaded. All of the selected videos are cut into clips of average 485 frames manually, in which there is no shot change.
Diverse Scenes
As for the diversity of video context, football games provide outdoor scenes and the rest results provide indoor scenes. Furthermore, the views of the playing courts do vary, which include common side view of crowded audience like in NBA, views from the serve zone in volleyball games, and aerial view in football games. Diverse scenes in our dataset will encourage the algorithms to generalize to different sports tracking settings
Basic Statstics
| Category(avg.) | #frames | #tracks | track gap len | track length | #bboxes per frame (density) |
|---|---|---|---|---|---|
| Basketball | 845.4 | 10 | 68.7 | 767.9 | 9.1 |
| Volleyball | 360.4 | 12 | 38.2 | 335.9 | 11.2 |
| Football | 673.9 | 20.5 | 116.1 | 422.1 | 12.8 |
basic statistics of videos of 3 categories.
Explanation for the statistics above 🔍
- track: number of tracks per video.
- tracklen: average length/number of frames per video
- fragmentation: average number of track fragmentation per video.
- speed: average speed of the players in videos.
- density: average number of players per frame per video.
- bboxsize: average size of bounding boxes(pixels).
- defrate: average
deformationRate
We use deformation rate to measure the degree of deformation. Here,

Distributions(Gaussian PDF) of the fragment speed in 3 sports in SportsMOT.
Motivation
Multi-object tracking (MOT) is a fundamental task in computer vision, aiming to estimate objects (e.g., pedestrians and vehicles) bounding boxes and identities in video sequences.
Prevailing human-tracking MOT datasets mainly focus on pedestrians in crowded street scenes (e.g., MOT17/20) or dancers in static scenes (DanceTrack).
In spite of the increasing demands for sports analysis, there is a lack of multi-object tracking datasets for a variety of sports scenes, where the background is complicated, players possess rapid motion and the camera lens moves fast.
To this purpose, we propose a large-scale multi-object tracking dataset named SportsMOT, consisting of 240 video clips from 3 categories (i.e., basketball, football and volleyball).
The objective is to only track players on the playground (i.e., except for a number of spectators, referees and coaches) in various sports scenes. We expect SportsMOT to encourage the community to concentrate more on the complicated sports scenes.
Data Format
Data in SportsMOT is organized in the form of MOT Challenge 17.
Unzip the provided .zip file, you will get
splits_txt(video-split mapping)-
basketball.txt -
volleyball.txt -
football.txt -
train.txtdetails
v_-6Os86HzwCs_c001 v_-6Os86HzwCs_c003 v_-6Os86HzwCs_c007 v_-6Os86HzwCs_c009 v_2j7kLB-vEEk_c001 v_2j7kLB-vEEk_c002 -
val.txt -
test.txt
-
scriptsmot_to_coco.pysportsmot_to_trackeval.py
dataset(in MOT challenge format)trainVIDEO_NAME1-
gtdetails
1, 7, 749, 217, 34, 125, 1, 1, 1 1, 8, 721, 344, 71, 120, 1, 1, 1 1, 9, 847, 352, 50, 151, 1, 1, 1 2, 0, 85, 421, 88, 131, 1, 1, 1 -
img1000001.jpg000002.jpg
-
seqinfo.inidetails
[Sequence] name=v_-6Os86HzwCs_c001 imDir=img1 frameRate=25 seqLength=825 imWidth=1280 imHeight=720 imExt=.jpg
-
val- the same hierarchy as train
testVIDEO_NAME1img1000001.jpg000002.jpg
seqinfo.ini
You can download the example for SportsMOT.
- OneDrive
- Baidu Netdisk, password: 4dnw
Usage
Download
Please Sign up in codalab, and participate in our competition. Download links are available in Participate/Get Data.
Format Conversion
Refer to codes/conversion
Evaluation Kit
Refer to codes/evaluation for out-of-the-box evaluation based on TrackEval and how to use. 🕹️
Contact
This track is provide by MCG Group @ Nanjing University, Jiangsu, China.
- Limin Wang
- Yutao Cui
- Xiaoyu Zhao
- Chenkai Zeng
- Yichun Yang
Valuable issues and chat are welcomed.
Terms
SportsMOT is allowed to be used only if you accept these terms and conditions of our competition.
- You agree to us storing your submission results for evaluation purposes.
- You agree that if you place in the top-10 at the end of the challenge you will submit your code so that we can verify that you have not cheated.
- You agree not to distribute the SportsMOT dataset without prior written permission.
- Each team can have one or more members.

SportsMOT is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Citation
@article{cui2023sportsmot,
title={SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes},
author={Cui, Yutao and Zeng, Chenkai and Zhao, Xiaoyu and Yang, Yichun and Wu, Gangshan and Wang, Limin},
journal={arXiv preprint arXiv:2304.05170},
year={2023}
}