


![]()


Melody is a language that compiles to ECMAScript regular expressions, while aiming to be more readable and maintainable.
Examples
Note: these are for the currently supported syntax and may change
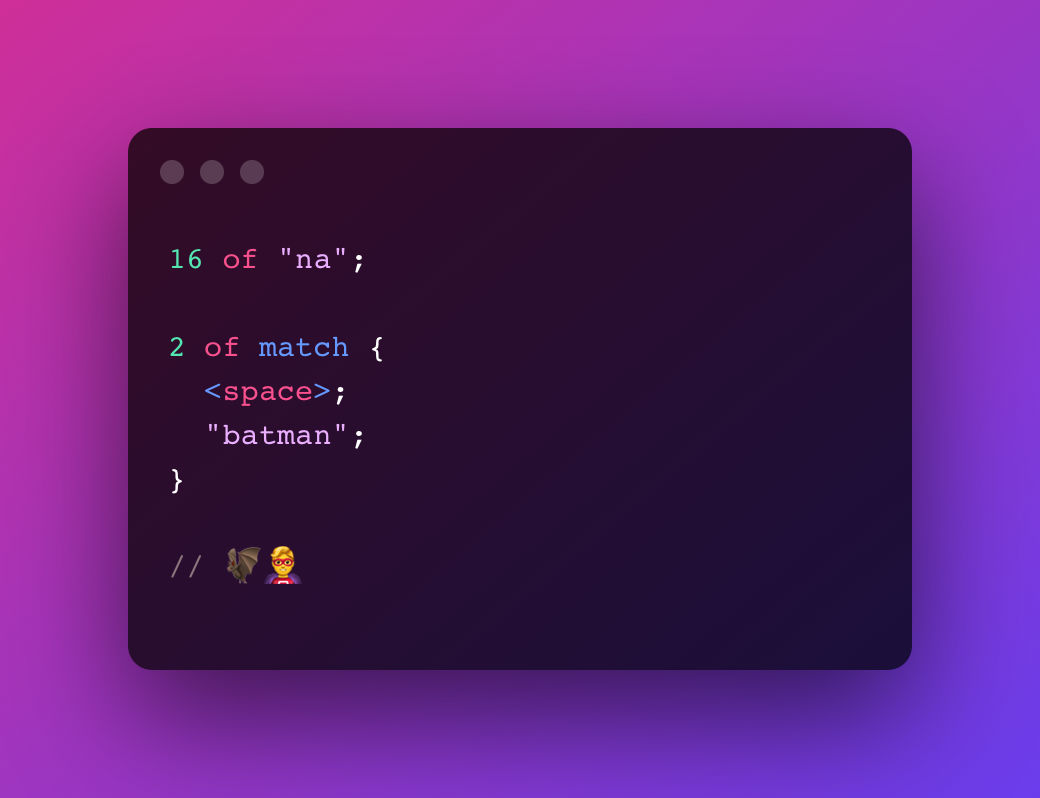
Batman Theme try in playground
16 of "na";
2 of match {
<space>;
"batman";
}
// 🦇🦸♂️Turns into
(?:na){16}(?: batman){2}Twitter Hashtag try in playground
"#";
some of <word>;
// #melodyTurns into
#\w+Introductory Courses try in playground
some of <alphabetic>;
<space>;
"1";
2 of <digit>;
// classname 1xxTurns into
[a-zA-Z]+ 1\d{2}Indented Code (2 spaces) try in playground
some of match {
2 of <space>;
}
some of <char>;
";";
// let value = 5;Turns into
(?: {2})+.+;Semantic Versions try in playground
<start>;
option of "v";
capture major {
some of <digit>;
}
".";
capture minor {
some of <digit>;
}
".";
capture patch {
some of <digit>;
}
<end>;
// v1.0.0Turns into
^v?(?<major>\d+)\.(?<minor>\d+)\.(?<patch>\d+)$Playground
You can try Melody in your browser using the playground
Book
Read the book here
Install
Cargo
cargo install melody_cliFrom Source
git clone https://github.com/yoav-lavi/melody.git
cd melody
cargo install --path crates/melody_cliBinary
- macOS binaries (
aarch64andx86_64) can be downloaded from the release page
Community
-
Brew (macOS and Linux)
Installation instructions
brew install melody
-
Arch Linux (maintained by @ilai-deutel)
Installation instructions
-
Installation with an AUR helper, for instance using
paru:paru -Syu melody
-
Install manually with
makepkg:git clone https://aur.archlinux.org/melody.git cd melody makepkg -si
-
-
Installation instructions
-
Declarative installation using
/etc/nixos/configuration.nix:{ pkgs, ... }: { environment.systemPackages = with pkgs; [ melody ]; }
-
Imperative installation using
nix-env:nix-env -iA nixos.melody
-
CLI Usage
USAGE:
melody [OPTIONS] [INPUT_FILE_PATH]
ARGS:
<INPUT_FILE_PATH> Read from a file
Use '-' and or pipe input to read from stdin
OPTIONS:
-f, --test-file <TEST_FILE>
Test the compiled regex against the contents of a file
--generate-completions <COMPLETIONS>
Outputs completions for the selected shell
To use, write the output to the appropriate location for your shell
-h, --help
Print help information
-n, --no-color
Print output with no color
-o, --output <OUTPUT_FILE_PATH>
Write to a file
-r, --repl
Start the Melody REPL
-t, --test <TEST>
Test the compiled regex against a string
-V, --version
Print version information
Changelog
See the changelog here or in the release page
Syntax
Quantifiers
... of- used to express a specific amount of a pattern. equivalent to regex{5}(assuming5 of ...)... to ... of- used to express an amount within a range of a pattern. equivalent to regex{5,9}(assuming5 to 9 of ...)over ... of- used to express more than an amount of a pattern. equivalent to regex{6,}(assumingover 5 of ...)some of- used to express 1 or more of a pattern. equivalent to regex+any of- used to express 0 or more of a pattern. equivalent to regex*option of- used to express 0 or 1 of a pattern. equivalent to regex?
All quantifiers can be preceded by lazy to match the least amount of characters rather than the most characters (greedy). Equivalent to regex +?, *?, etc.
Symbols
<char>- matches any single character. equivalent to regex.<space>- matches a space character. equivalent to regex<whitespace>- matches any kind of whitespace character. equivalent to regex\sor[ \t\n\v\f\r]<newline>- matches a newline character. equivalent to regex\n<tab>- matches a tab character. equivalent to regex\t<return>- matches a carriage return character. equivalent to regex\r<feed>- matches a form feed character. equivalent to regex\f<null>- matches a null characther. equivalent to regex\0<digit>- matches any single digit. equivalent to regex\dor[0-9]<vertical>- matches a vertical tab character. equivalent to regex\v<word>- matches a word character (any latin letter, any digit or an underscore). equivalent to regex\wor[a-zA-Z0-9_]<alphabetic>- matches any single latin letter. equivalent to regex[a-zA-Z]<alphanumeric>- matches any single latin letter or any single digit. equivalent to regex[a-zA-Z0-9]<boundary>- Matches a character between a character matched by<word>and a character not matched by<word>without consuming the character. equivalent to regex\b<backspace>- matches a backspace control character. equivalent to regex[\b]
All symbols can be preceeded with not to match any character other than the symbol
Special Symbols
<start>- matches the start of the string. equivalent to regex^<end>- matches the end of the string. equivalent to regex$
Unicode Categories
Note: these are not supported when testing in the CLI (-t or -f) as the regex engine used does not support unicode categories. These require using the u flag.
<category::letter>- any kind of letter from any language<category::lowercase_letter>- a lowercase letter that has an uppercase variant<category::uppercase_letter>- an uppercase letter that has a lowercase variant.<category::titlecase_letter>- a letter that appears at the start of a word when only the first letter of the word is capitalized<category::cased_letter>- a letter that exists in lowercase and uppercase variants<category::modifier_letter>- a special character that is used like a letter<category::other_letter>- a letter or ideograph that does not have lowercase and uppercase variants
<category::mark>- a character intended to be combined with another character (e.g. accents, umlauts, enclosing boxes, etc.)<category::non_spacing_mark>- a character intended to be combined with another character without taking up extra space (e.g. accents, umlauts, etc.)<category::spacing_combining_mark>- a character intended to be combined with another character that takes up extra space (vowel signs in many Eastern languages)<category::enclosing_mark>- a character that encloses the character it is combined with (circle, square, keycap, etc.)
<category::separator>- any kind of whitespace or invisible separator<category::space_separator>- a whitespace character that is invisible, but does take up space<category::line_separator>- line separator character U+2028<category::paragraph_separator>- paragraph separator character U+2029
<category::symbol>- math symbols, currency signs, dingbats, box-drawing characters, etc<category::math_symbol>- any mathematical symbol<category::currency_symbol>- any currency sign<category::modifier_symbol>- a combining character (mark) as a full character on its own<category::other_symbol>- various symbols that are not math symbols, currency signs, or combining characters
<category::number>- any kind of numeric character in any script<category::decimal_digit_number>- a digit zero through nine in any script except ideographic scripts<category::letter_number>- a number that looks like a letter, such as a Roman numeral<category::other_number>- a superscript or subscript digit, or a number that is not a digit 0–9 (excluding numbers from ideographic scripts)
<category::punctuation>- any kind of punctuation character<category::dash_punctuation>- any kind of hyphen or dash<category::open_punctuation>- any kind of opening bracket<category::close_punctuation>- any kind of closing bracket<category::initial_punctuation>- any kind of opening quote<category::final_punctuation>- any kind of closing quote<category::connector_punctuation>- a punctuation character such as an underscore that connects words<category::other_punctuation>- any kind of punctuation character that is not a dash, bracket, quote or connectors
<category::other>- invisible control characters and unused code points<category::control>- an ASCII or Latin-1 control character: 0x00–0x1F and 0x7F–0x9F<category::format>- invisible formatting indicator<category::private_use>- any code point reserved for private use<category::surrogate>- one half of a surrogate pair in UTF-16 encoding<category::unassigned>- any code point to which no character has been assigned
These descriptions are from regular-expressions.info
Character Ranges
... to ...- used with digits or alphabetic characters to express a character range. equivalent to regex[5-9](assuming5 to 9) or[a-z](assuminga to z)
Literals
"..."or'...'- used to mark a literal part of the match. Melody will automatically escape characters as needed. Quotes (of the same kind surrounding the literal) should be escaped
Raw
`...`- added directly to the output without any escaping
Groups
capture- used to open acaptureor namedcaptureblock. capture patterns are later available in the list of matches (either positional or named). equivalent to regex(...)match- used to open amatchblock, matches the contents without capturing. equivalent to regex(?:...)either- used to open aneitherblock, matches one of the statements within the block. equivalent to regex(?:...|...)
Assertions
ahead- used to open anaheadblock. equivalent to regex(?=...). use after an expressionbehind- used to open anbehindblock. equivalent to regex(?<=...). use before an expression
Assertions can be preceeded by not to create a negative assertion (equivalent to regex (?!...), (?<!...))
Variables
-
let .variable_name = { ... }- defines a variable from a block of statements. can later be used with.variable_name. Variables must be declared before being used. Variable invocations cannot be quantified directly, use a group if you want to quantify a variable invocationexample:
let .a_and_b = { "a"; "b"; } .a_and_b; "c"; // abc
Extras
/* ... */,// ...- used to mark comments (note:// ...comments must be on separate line)
File Extension
The Melody file extensions are .mdy and .melody
Crates
melody_compiler- The Melody compiler📦 📖 melody_cli- A CLI wrapping the Melody compiler📦 📖 melody_wasm- WASM bindings for the Melody compiler
Extensions
Packages
Integrations
Performance
Last measured on v0.19.0
Measured on an 8 core 2021 MacBook Pro 14-inch, Apple M1 Pro using criterion:
-
8 lines:
compiler/normal (8 lines) time: [4.0579 µs 4.0665 µs 4.0788 µs] slope [4.0579 µs 4.0788 µs] R^2 [0.9996538 0.9995633] mean [4.0555 µs 4.0806 µs] std. dev. [11.018 ns 26.342 ns] median [4.0500 µs 4.0852 µs] med. abs. dev. [5.6889 ns 35.806 ns] -
1M lines:
compiler/long input (1M lines) time: [400.97 ms 402.31 ms 403.53 ms] mean [400.97 ms 403.53 ms] std. dev. [773.42 µs 2.9886 ms] median [401.22 ms 403.39 ms] med. abs. dev. [59.042 µs 3.5129 ms] -
Deeply nested:
compiler/deeply nested time: [5.8085 µs 5.8291 µs 5.8514 µs] slope [5.8085 µs 5.8514 µs] R^2 [0.9992861 0.9992461] mean [5.8064 µs 5.8519 µs] std. dev. [21.027 ns 49.152 ns] median [5.7949 µs 5.8583 µs] med. abs. dev. [3.3348 ns 64.628 ns]
To reproduce, run cargo bench or cargo xtask benchmark
Future Feature Status
❌ - Not implemented
| Melody | Regex | Status |
|---|---|---|
not "A"; |
[^A] |
|
| variables / macros | ||
<...::...> |
\p{...} |
|
not <...::...> |
\P{...} |
|
| file watcher | ||
| multiline groups in REPL | ||
flags: global, multiline, ... |
/.../gm... |
|
| (?) | \# |
|
| (?) | \k<name> |
|
| (?) | \uYYYY |
|
| (?) | \xYY |
|
| (?) | \ddd |
|
| (?) | \cY |
|
| (?) | $1 |
|
| (?) | $` |
|
| (?) | $& |
|
| (?) | x20 |
|
| (?) | x{06fa} |
|
any of "a", "b", "c" * |
[abc] |
|
| multiple ranges * | [a-zA-Z0-9] |
❓ |
| regex optimization | ||
| standard library / patterns | ||
| reverse compiler |
* these are expressable in the current syntax using other methods