
Commonsense Knowledge Aware Conversation Generation with Graph Attention
Introduction
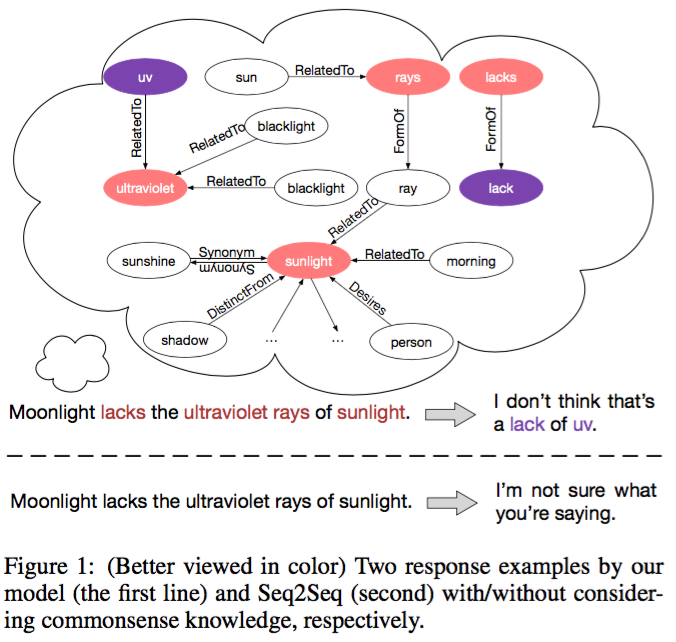
Commonsense knowledge is vital to many natural language processing tasks. In this paper, we present a novel open-domain conversation generation model to demonstrate how large-scale commonsense knowledge can facilitate language understanding and generation. Given a user post, the model retrieves relevant knowledge graphs from a knowledge base and then encodes the graphs with a static graph attention mechanism, which augments the semantic information of the post and thus supports better understanding of the post. Then, during word generation, the model attentively reads the retrieved knowledge graphs and the knowledge triples within each graph to facilitate better generation through a dynamic graph attention mechanism, as shown in Figure 1.
This project is a tensorflow implement of our work, CCM.
Dependencies
- Python 2.7
- Numpy
- Tensorflow 1.3.0
Quick Start
-
Dataset
Commonsense Conversation Dataset contains one-turn post-response pairs with the corresponding commonsense knowledge graphs. Each pair is associated with some knowledge graphs retrieved from ConceptNet. We have applied some filtering rules to retain high-quality and useful knowledge graphs.
Please download the Commonsense Conversation Dataset to data directory.
-
Train
python main.pyThe model will achieve the expected performance after 20 epochs.
-
Test
python main.py --is_train FalseYou can test the model using this command. The statistical result and the text result will be output to the 'test.res' file and the 'test.log' file respectively.
Details
Training
You can change the model parameters using:
--units xxx the hidden units
--layers xxx the number of RNN layers
--batch_size xxx batch size to use during training
--per_checkpoint xxx steps to save and evaluate the model
--train_dir xxx training directory
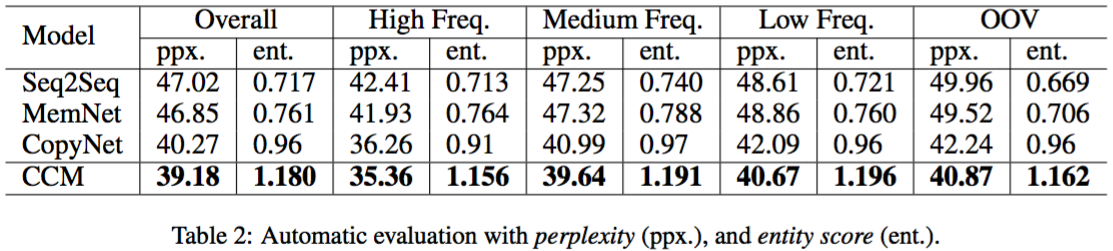
Evaluation
Paper
Hao Zhou, Tom Yang, Minlie Huang, Haizhou Zhao, Jingfang Xu, Xiaoyan Zhu.
Commonsense Knowledge Aware Conversation Generation with Graph Attention.
IJCAI-ECAI 2018, Stockholm, Sweden.
Please kindly cite our paper if this paper and the code are helpful.
Acknowlegments
Thanks for the kind help of Prof. Minlie Huang and Prof. Xiaoyan Zhu. Thanks for the support of my teammates.
License
Apache License 2.0