
Ape-X
An Implementation of Distributed Prioritized Experience Replay (Horgan et al. 2018) in PyTorch.

The paper proposes a distributed architecture for deep reinforcement learning with distributed prioritized experience replay. This enables a fast and broad exploration with many actors, which prevents model from learning suboptimal policy.
There are a few implementations which are optimized for powerful single machine with a lot of cores but I tried to implement Ape-X in a multi-node situation with AWS EC2 instances. ZeroMQ, AsyncIO, Multiprocessing are really helpful tools for this.
There are still performance issues with replay server which are caused by the shared memory lock and hyperparameter tuning but this works anyway. Also, there are still some parts I hard-coded for convenience. I'm trying to improve many parts and really appreciate your help.
Requirements
python 3.7
numpy==1.16.2
torch==1.0.0.dev20190303
pyzmq==18.0.0
opencv-python==4.0.0.21
tensorflow==1.13.0
tensorboardX==1.6
gym==0.12.0
gym[atari]
numpy=1.16.0version has memory leak issue with pickle so try not to use numpy 1.16.0.- CPU performance of
pytorch-nightly-cpufrom conda is much better than normaltorch tensorflowis necessary to use tensorboardX.
Overall Structure

Result
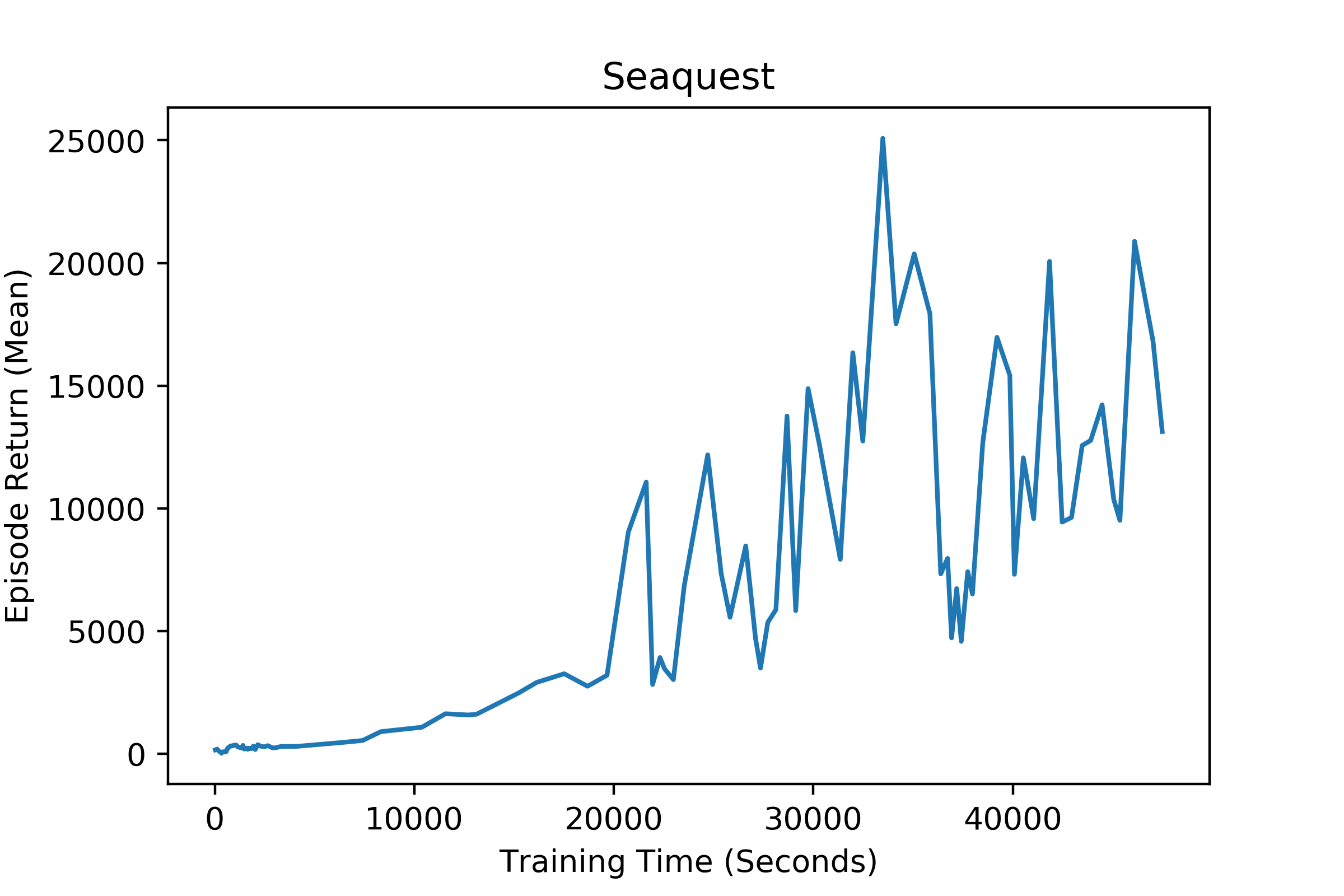
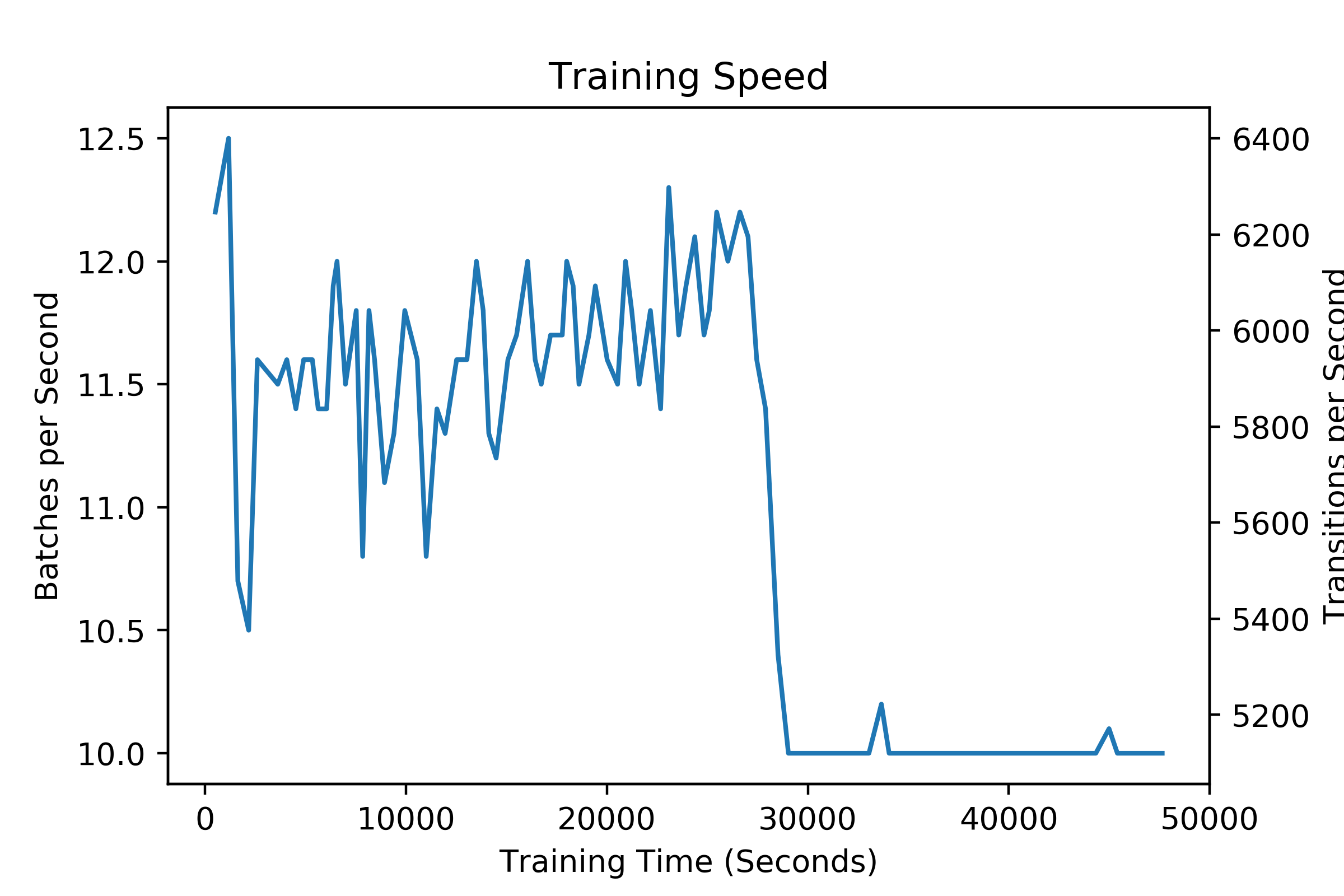

Seaquest result trained with 192 actors. Due to the slow training speed(10~12 batches/s instead of 19 batches/s in paper), It was not possible to reproduce the same result as the paper. But it shows dramatic increase over my baseline implementations(rainbow, acer)
Added gif to show how agent really acts and scores in SeaquestNoFrameskip-v4. I recently noticed that the performance(score) of actor is much better in evaluation setting(epsilon=0.) than the plot 1.
How To Use
Single Machine
My focus was to run Ape-X in a multi-node environment but you can run this model with powerful single machine. I have not run any experiment with single machine so I'm not sure you can achieve satisfactory performance/result. For details, you can see run.sh included in this repo.
Multi-Node with AWS EC2
Be careful not to include your private AWS secret/access key in public repository while following instructions!
Packer

Packer is a useful tool to build automated machine images. You'll be able to make AWS AMI with a few line of json formatted file and shell script. There are a lot of more available features in packer's website. I've made all necessary files in deploy/packer directory. If you're not interested in using packer, I already included pre-built AMI in variables.tf so you can skip this part.
- Enter your secrey/access key with appropriate IAM policy in
variables.jsonfile. - run below commands in parallel.
packer build -var-file=variables.json ape_x_actor.json packer build -var-file=variables.json ape_x_replay.json packer build -var-file=variables.json ape_x_learner.json - You can see AMIs are created in your AWS account.
Terraform

Terraform is a useful IaC(Infrastructure as Code) tool. You can start multiple instances with only one command terraform apply and destroy all instances with terraform destroy. For more information, See Terraform's website tutorial and documentation. I have already included all necessary commands in deploy directory. Important files are deploy.tf, variables.tf, terraform.tfvars.
- Read
variables.tfand enter necessary values toterraform.tfvars. Values included interraform.tfvarswill override any default values invariables.tf. - Change EC2 instance type in
deploy.tfto meet your budget. - Run
terraform initindeploydirectory. - Run
terraform applyand terraform will magically create all necessary instances and training will start. - To see how trained model works, See tensorboard which includes actor with larget actor id which has smallest epsilon value. You could easily access tensorboard by entering http://public_ip:6006. Or you could add a evaluator node with a new instance but this costs you more money :(